Intro
SDN Lullaby는 SDN/NFV 환경에서 효율적인 VNF 배치에 관하여 작성한 논문이다. 이 논문에서는 VNF 배치 문제를 DRL을 이용하여 해결하였다. 이를 위해서, 해당 논문에서는 상용 Cloud Data Center에서 주로 사용되던 VM Consolidation 방식을 활용하였고, 이 과정에서 추가적인 구현을 더해서 VNF 배치 문제를 해결하였다. 해당 Posting에서는 이를 구현 및 작성하는 과정에서 겪은 문제를 기반으로 한 회고록이다.
Description
우선 해당 프로젝트를 통해서 해결하고자 했던 문제부터 정의하자면, 간단하게 SDN/NFV 환경에서 수 많은 VNF가 Virtual Machine(VM)의 형태로 존재하게 되는데 이를 Network Performance와 Energy Efficiency를 모두 고려하여 효율적으로 배치하는 것이 굉장히 어렵고, Rule based 방식으로는 한계가 있는 NP-Hard 문제라는 것이다. 이를 해결하기 위해서 해당 논문에서는 DRL 방식 중에서 PPO를 활용한 해결책을 제시하였고, 성능은 Rule based 방식보다 System Load가 낮은 경우에는 더 성능이 좋았지만, 높은 경우는 오히려 성능이 떨어졌다.
자세한 설명은 CNSM 2023 에 오늘(2023/07/11) 제출하였기 때문에 결과가 나오면 추가로 업데이트하도록 하겠다. 일단은 구현에 대한 모든 내용은 Github SDN Lullaby에서 볼 수 있다.
Process
해당 프로젝트의 시작은 연구실에서 진행 중인 프로젝트 중 외국인 학생에게 할당되어있던 파트가 통채로 나에게 넘어오면서 시작된다. 프로젝트를 이어 받아서 유지, 보수하는 것으로 얘기가 되고 있었는데 사실상 구현이 거의 되어있지 않다는 것을 알게 되었다. 결국 그 학생은 이미 떠나갔고, 결국 나는 이를 처음부터 구현해야하는 상황에 놓여졌다. 이것이 4월 20일 나에게 주어진 미션이였다.
우선 큰 흐름에서는 기존 외국인 학생이 제시한 방향인 강화학습을 활용한 VM Consolidation으로 가닥을 잡았다. 하지만, 실제 요구사항에 대한 정의가 애매했기에 이 부분은 랩미팅과 기존 자료들을 통해서 얻을 수 있었다.
초기에는 여러 다른 논문을 찾아보면서, 어떤 구현이 가장 타당한지에 대한 조사를 진행하였다. 이 과정에서 VM Consolidation은 Server Selection, VM Selection, VM Placement 3단계로 나누어진다는 것을 알게 되었다. 즉, 어떤 서버에서 VM을 옮길지를 먼저 선택한 후에 해당 Server에서 어떤 VM을 선택할지를 결정한 후, 마지막으로 해당 VM을 어느 Server로 옮길지를 결정하는 것이다. 하지만, 해당 논문들을 읽으면서 든 생각은 왜 첫 번째 단계인 Server Selection이 왜 필요한가였다. 사실 결론적으로 원하는 것은 VM을 선택하고자 하는 것다. 즉, Server Selection은 선택하고자 하는 VM을 제한하는 역할을 수행한다. 이는 잘못된 추론을 하는 경우에 명백하게 편향적인 선택이 될 수 밖에 없다. 따라서, 해당 프로젝트에서는 과감하게 해당 단계를 생략하고 두 단계로 진행하는 것을 목표로 하였다. (VM Selection, VM Placement) 또한, 알고리즘을 선택하는 과정에서는 처음에는 강화학습 중에서도 기본적인 SARSA, Q-Learning을 적용하여 해당 문제를 푸는 것을 목표로 하였다. 하지만, Server의 상태(State)를 강화학습의 Input으로 주는 과정에서 문제가 발생했다. Input으로 전달해야할 정보는 Server의 상태, VM의 상태, 전체 Server를 포함하는 Edge의 상태 등이 있었는데 이를 모두 하나의 State로 정의하는데에는 한계가 있었기 때문이다. 이는 VM의 수와 Server의 수가 늘어남에 따라 제곱으로 State와 Action의 갯수가 늘어나기 때문에 이를 모두 하나의 Table로 표현하는 단순한 SARSA, Q-Learning으로는 한계가 있다는 것을 깨달았다. 따라서, 이를 해결하기 위해서 두 가지 선택지 중에서 하나를 골라야했다.
- State를 압축할 수 있는 방법을 찾는다.
- Deep Learning을 적용하여, Table을 Network로 추정하자.
랩미팅 과정에서 교수님은 1번을 강조하셨다. State를 압축할 수 있는 방법을 찾는다. 굉장히 간단한 알고리즘만으로도 해결이 가능할 것이라고 얘기하셨다. 하지만, 초기에는 이에 대한 감을 잡지 못했기 때문에 결론적으로는 2번을 선택했다. 사실 State가 많아진다면, 간단한 DQN(Deep Q Network)만 활요하더라도 어느정도 성능을 챙길 수 있을 것이라고 생각했고, State를 압축할 방법이 당시로서는 생각하기 어려웠다.
따라서, DQN을 활용하여 문제를 해결하는 것을 바로 시도하였다. 여기서도 결국 문제에 부딪히게 된다. 바로 State를 모두 활용하는 것까지는 좋은데 Output의 크기가 계속 변화하면 어떻게 할 것인지에 대한 문제를 해결할 수 없었다. 즉, 우리가 원하는 VM Consolidation은 결국 어떤 VM을 어떤 Server로 옮길지를 결정해야 한다. 그렇다면, 매 사건마다 Server와 VM의 갯수가 달라질 수가 있다는 것이다. 일반적으로는 Server의 갯수가 변화하는 일은 흔치 않지만, VM은 매번 바뀔 것이다. 따라서, 우리가 고를 VM의 갯수를 해당 System에서는 Input State가 주어지기 전까지는 알 수 없기 때문에 Deep Learning Model의 Output의 크기를 알 수가 없다는 것이다. 즉, Input과 Output의 크기를 정해놓고 시작하는 일반적인 Deep Learning Model로는 한계가 있다는 것이다. 이를 해결하기 위해서 결국 RNN을 활용하기로 결정한다. 즉, RNN에 Input으로 주어지는 데이터가 (Batch size, Sequence length, Input size)의 형태로 주어졌을 때, output의 형태는 (Batch size, Sequence length, Output size)와 같다. 여기서 Sequence length는 변화하지 않는데, 내가 하고자 하는 작업이 사실은 VM/Server의 정보가 주어졌을 때, 하나의 VM/Server를 선택하는 일이기 때문에 VM/Server의 수만큼 Sequence를 만들고, 여기서 나오는 Output size를 1로 고정한다면, 결국 어떤 크기의 VM/Server 수가 들어오더라도 그만큼의 Output을 보장받을 수 있었다. 따라서, 이를 활용해서 초기에는 LSTM에 기반한 DQN 모델을 구현하였다. 여기서 RNN(LSTM을 포함한)은 사실 Sequence를 거치면서 값을 누적하기 때문에, 우리의 원래 의도랑은 다르게 어느 위치에 Input 데이터를 넣느냐가 영향을 미칠 것이라는 것을 생각해서 이를 완화시키기 위해서 Bi-Direction으로 LSTM을 구성하였다. 이렇게 구성한 모델은 아래와 같다.
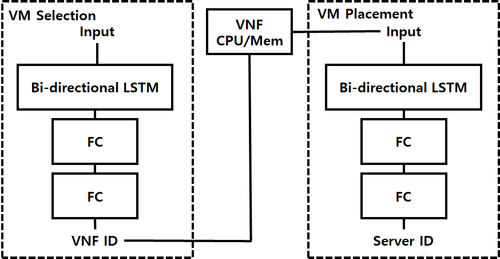
이를 실험하기 위해서, Emulation 환경도 구현을 해서 실험을 한 결과 서버 4개 정도에서 정상적으로 Consolidation이 진행되는 것을 확인했다. 하지만, 실제로 서버 갯수가 8개를 넘기자 전체적으로 성능이 떨어지는 것을 관측했다. 또한, 학습 과정에서 VM의 갯수가 Episode마다 유동적으로 변화하기 때문에 Batch 단위의 학습을 하기 위해서, Memory에 저장하는 과정에서 Episode Length마다 별도의 공간에 따로 저장하였다. 그리고, 학습을 진행할 때에는 Random하게 Length를 하나 선택해서 Episode를 추출했는데, 어떤 Length를 선택하냐에 따라서도 값의 변화가 크기 때문에 이 구조가 variance를 더 크게 할 것이라는 결론에 도달했다. 따라서, 이 문제를 해결하기 위해서 다음과 같은 해결책을 생각했다.
- Self Attention 구조 적용(LSTM -> Self Attention)
- Zero Padding 추가
앞 서 제시했던 Bi Direction을 활요한 LSTM은 설계 자체가 Hidden Value를 순서대로 추출해나가면서 이득을 취하는 것인데 해당 구조에서는 각 요소의 특징을 입력으로 받아서 어떤 요소를 선택할지에 관한 문제이기 때문에 Self Attention 구조가 더 적절하다는 판단을 했다. 또한, zero padding을 추가하여 모든 데이터를 한 번에 저장하였다. 또한, 추가적으로 불가능한 Action의 선택을 방지하기 위해서 추가적인 preprocessing을 추가하였다. 즉, 옮길 수 있는 서버가 없는 VM인 경우, 선택한 VM을 옮길 수 없는 경우는 미리 filtering을 수행하여 해당 데이터를 zero 로 marking하였다. 이를 통해서, 불가능한 Action을 선택하는 것을 방지하였다. 따라서, 이를 반영하여 변경된 구조는 다음과 같다.
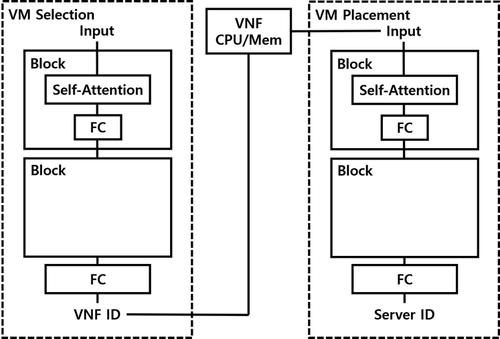
하지만, 전체적인 성능 개선이 이루어지지 않았고, 따라서 이를 해결하기 위해서 AlphaStar라는 논문을 참고하였다. 해당 구조에서는 아래와 같은 구조를 보여준다.
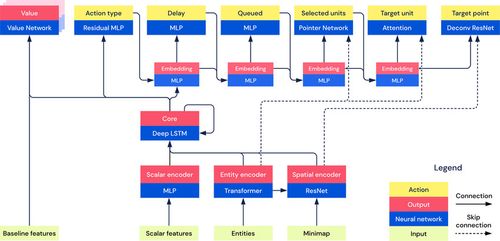
여기서는 Encoding Layer를 두고, 이후에 LSTM을 통해서 Sequence 정보를 입력받고, 후에 이를 기반으로 Action을 선택하는 구조를 갖고 있다. 또한, 여기서 특정 Unit을 선택하기 위해서 Self Attention과 Attention을 혼합하여 사용하는 것을 보고 내가 위에서 VM/Server Selection에 Attention Mechanism을 사용하는 것이 일반적인 해결책이라는 것을 알게 되었다. 어쨌든, 이름 참고하여 다음과 같은 구조를 구현했다. 여기서는 DQN이 아닌 PPO를 적용하였다.
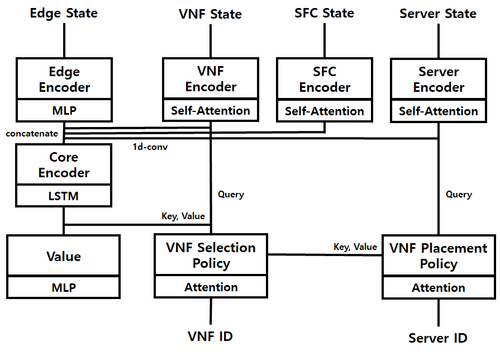
해당 구조를 통한 실험 역시 실행하였지만, 전체적인 성능 역시 변화하지 않았다. 그래서 결론적으로 최종적으로 두 가지 구조를 변형하여 구현을 마무리하였다. 먼저, 기존 DQN 구조에서 input layer를 추가하여 PPO 구조로 변경하는 것, 그리고 불가능한 Action에 대한 filtering을 preprocessing이 아닌 postprocessing으로 수행하는 것이다. Preprocessing을 수행하는 경우에는 결론적으로 정보의 손실이 발생하게 되는데 이로 인한 손해를 보지말고 차라리 최종 선택 단계에서 불가능한 Action을 선택할 확률을 0이 되도록 postprocessing하는 방식으로 변경하였다. 따라서, 최종 구조는 다음과 같다.
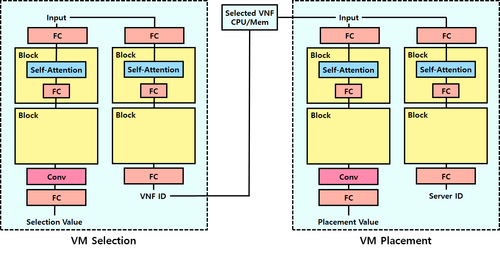
해당 최종 구조를 통해서 결론적으로 에너지 효율성과 네트워크 처리 능력까지 향상하는 결과를 얻을 수 있었다. (이는 논문과 Github에 업로드된 자료를 확인하도록 하자.)
Opinion
결론적으로 나의 첫 번째 Full Paper 논문이 였기에 아쉬움도 많이 남지만, 애착도 그만큼이나 남을 것으로 생각하고 있다. 먼저 총평을 하자면, 나름 만족할만한 프로젝트였다고 생각한다. 우선 랩 미팅마다 매주 progress를 발표하고, 논의하는 과정 자체가 굉장히 유의미했다고 생각한다. 그 때 작성한 자료들이 지금 작성하고 있는 글 그리고 얼마 전에 제출한 논문을 작성하는데 많은 도움을 주었다. 따라서, progress를 주 단위나 작업 단위로 정리하는 것은 굉장히 중요하다는 것을 다시 한 번 느꼈다. 그리고, 실제로 Deep Learning과 Reinforcement Learning을 활용하여 Project를 직접 구현한 것은 이번이 처음이기 때문에 굉장히 많은 걱정을 하였는데 많은 사람들의 도움을 받고 여러 책곽 논문의 도움을 받아서 결국 성공적으로 마무리했다는 것이 중요한 경험으로 남을 거 같다. 또한, 문제를 정의하는 것이 가장 중요하고, 여러 논문을 찾는 사전 준비 단계가 반 이상이라는 것을 깨달았다. 이 과정이 탄탄해야 막힘없이 진행이 가능한데 이를 초기에는 간과한 거 같아서 앞으로는 초반 준비 단계에서 자료 찾고 읽는 것에 굉장히 집중해야겠다는 생각이 들었다. 그리고, 구현하는 과정에서도 관련 자료가 있으면 계속해서 읽어보는 것이 전체적인 구현의 질을 높일 수 있다는 것을 다시 한 번 상기할 수 있는 기회였다.
해당 프로젝트를 하면서, 만족했던 점은 다음과 같다.
- 이때까지 프로젝트를 진행하면서, 내가 항상 가지는 마인드는 "어떠한 판단을 하였다면, 이에 대한 근거를 항상 제시할 수 있어야 한다." 였는데 이는 해당 프로젝트에서는 꽤나 잘 지켜진 거 같아서 만족한다.
- 정리를 굉장히 잘 해두었다. 발표 자료 및 자료 조사 내용 정리를 굉장히 잘 해두었고, 이를 통해서 논문 작성에도 큰 도움을 받았다.
아쉬웠던 점은 다음과 같다.
- DRL은 처음 적용하다보니 여러 알고리즘을 실험해보고 싶었는데 결과적으로는 DQN, PPO 밖에 적용하지 못했다.
- 실험 결과를 내는 과정에서 시간이 굉장히 오래 걸렸다. 이는 실험을 진행하면서, 여러가지 문제가 발생했기 때문인데 이를 미리 예측하고 대비하지 못한 것이 아쉽다.
- 최종 구현의 Performance에 미련이 남는다. 결론적으로는 Baseline 시스템과 비교했을 때, 조금 좋은 부분이 있고, 어떤 부분에서는 매우 뒤떨어지기도 하는데 이에 대해서 General한 성능 향상이 있었다면 더 좋았겠다는 생각이 든다.
Reference
- For Thumbnail: Lullaby icons created by Freepik Flaticon
- For Thumbnail: Data server icons created by The Chohans Brand - Flaticon
- Arulkumaran, Kai, Antoine Cully, and Julian Togelius. "Alphastar: An evolutionary computation perspective." Proceedings of the genetic and evolutionary computation conference companion. 2019.





Comments