Intro
Blog를 검색 엔진들에 노출하기 위한 일지를 기록한다.
먼저 내가 원하는 것은 구글, 네이버, 다음에 나의 블로그의 태그, 카테고리, 타이틀로 검색어가 노출이 되는 것이다. 이를 위해서 무엇을 해야 하는지를 정리한다.
robots.txt
robots.txt는 CRA로 React Project를 생성했을 때도, 자동으로 생성해줄만큼 가장 기본적인 요소이다. 이는 가종 검색 엔진의 Posting을 Crawling하는 장치들에게 해당 Posting에 대한 접근 권한을 명시해놓는 곳이다. 따라서, 작성 시에는 간략하게 다음과 같이 표현하는 것이 일반적이다.
1User-agent: * 2Disallow:
이는 어떠한 검색 엔진 봇의 접근을 허락하며, 모든 하위 uri에 대한 접근을 허락한다는 것이다. 더 알고 싶다면 공식 문서를 참고하자. https://www.robotstxt.org/robotstxt.html
sitemap.xml
웹 페이지 내의 모든 페이지 목록을 나열한 파일이다. 이는 site에 해당하는 모든 url을 등록하고, 어느곳에 어느 컨텐츠가 존재하는지를 알려주는 mapping table이라고 볼 수 있다. 이를 명시해두어야만 후에 bot들이 작업을 할 때, 조회를 하여 사용할 수 있다.
next-sitemap이라는 도구를 이용해서 자동 생성하도록 설정을 해두었다.
이에 대한 설명은 다음 자료들을 확인해보도록 하자.
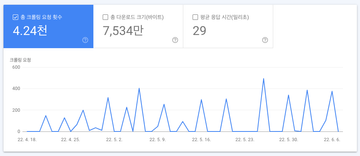
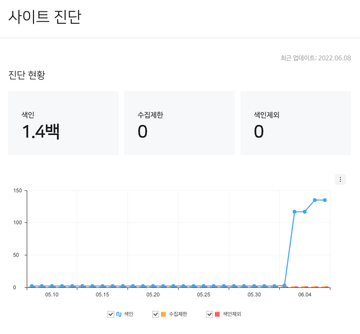
Naver에서는 sitemap을 등록해주어야만 정상적으로 수집하는 것을 볼 수 있었는데 구글에서는 바로바로 Crawling하는 것을 확인할 수 있었다.
Google Search Console
Naver Search Advisor
Metadata
결론적으로 말하면, SEO에서 가장 필요한 것이 Metadata의 정리이다. 그 중에서도 가장 핵심이 되는 것이 두 가지이다.
- title : 말 그대로 Posting의 제목이다.
- description : 말 그대로 Posting에 대한 요약 또는 소개 정도라고 보면 되겠다.
이를 적절히 설정해주면 이를 수집해가는 bot이 쉽게 이를 인식할 수 있고, 검색이 안정적으로 수행되어진다. 이를 위해서 해당 Blog에서는 NextJS를 통해서 title를 Posting 제목으로 지정하고, description은 본문의 Intro part를 기반으로 작성하도록 설정해두었다.
Open Graph
Metadata의 항목에 포함되는 OG를 제대로 설정하지 않으면 Naver에서는 이를 제대로 인식하지 않는다고하니 이 또한 제대로 입력해주도록 하자. 테스트 할 때에는 간단하게 Kakaotalk, Facebook 등으로 보내보며 제대로 노출이 되는지를 확인하면 된다.
Comments