Intro
해당 Posting은 Bitcoin이 무엇이고, 이것으로 무엇을 할 수 있는지에 대해서 설명하지 않고 Bitcoin을 구현하는 기술에 대하여 다룹니다. 또한, 책의 모든 내용을 충실히 번역하는 것이 아닌 작성자의 생각이 많이 담겨 있으니 유의 바랍니다.
해당 chapter에서는 Blockchain Network 구조에 대한 이해와 실용성을 향상하기 위한 MerkleTree, Bloom Filter, SigWit에 대해서 정리합니다.
이전 Chapter에서는 Transaction의 소유 여부를 확인하는 방법에 대해서 자세히 다루었습니다. 거기서 Transaction의 사용 여부를 확인할 때에는 UTXO(Unspent Transaction Output) set이라는 것을 사용한다고 하였습니다. 그렇다면, 이는 어떻게 생성되고, 어떻게 관리되는지를 해당 part에서 한 번 다루어보겠습니다.
1. Blockchain
우리의 Transaction을 저장하기 위해서 여러 가지 방법을 강구해보았습니다. 모든 Transaction을 표의 형태로 저장해두는 것도 방법이 될 수 있습니다. 하지만, Bitcoin에서는 이를 Block이라는 단위로 저장하였습니다.
1-1. Block
1-1-1. 정의
Block이란 Transaction을 저장하는 하나의 단위라고 볼 수 있습니다. 하나의 Block의 크기는 1MB로 제한되어있습니다. (물론 지금은 여러 다른 변종에서는 이 제한이 다르기도 합니다.)
1-1-2. 구조
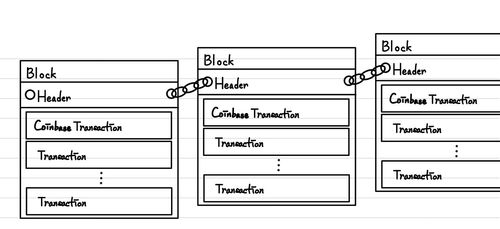
따라서, Block에는 이를 만족하는 Transaction의 갯수만큼만을 저장할 수 있습니다. 이를 이루는 구조는 다음과 같습니다.
- Header : 해당 Block에 대한 설명을 위한 정보를 포함합니다. 특히, 해당 Block의 정당성을 확인하기 위한 내용을 포함합니다.
- Coinbase Transaction : Block에 존재하는 첫번째 Transaction을 의미합니다.
- Transactions : 여러 user들의 거래 내용을 포함하는 내용입니다. 이 안에도 Block 생성자를 위한 보상이 포함됩니다. 보상이 없다면, 해당 transaction의 우선순위는 낮을 수밖에 없습니다.
1-1-3. Coinbase Transaction
기본적으로 모든 Transaction은 이전 Transaction의 Output을 가르키고 있어야 하며, 이것이 자신의 것이라는 증명을 포함해야 합니다. 그렇다면, 의문이 생기는 부분이 있습니다. 모든 Transaction의 끝으로 갔을 때, 과연 기반 Transaction은 어디서 오는가에 대한 고민을 하게 됩니다. 그것이 되는 것이 바로 이 Coinbase Transaction입니다. 이는 이전 Transaction의 Output 없이도 정의할 수 있습니다. 이는 해당 Block을 만들어낸 생성자에게 보상을 제공하는 의미에서 Bitcoin을 제공합니다. 해당 Transaction은 이전 Transaction을 가리키는 값이 모두 0으로 초기화되어있어 쉽게 식별이 가능합니다. 또한, 특이하게도, Coinbase Transaction의 정당성은 Block 자체가 증명하기 때문에, input의 ScriptSig 부분은 무의미한 데이터가 됩니다. 따라서, 여기에는 자신만의 철학을 담은 문구를 사용할 수도 있었습니다. 하지만, 시간이 좀 흐른 후에는 여기에 Block의 height(제일 첫 번째 Block과의 거리)를 표시하는 용도로 사용합니다.
왜 Block을 생성한 사람에게 Bitcoin을 제공하는 것일까요? 이는 이제 앞으로 살펴볼 PoW에서 다루겠습니다.
1-1-4. Header
Header는 총 6개의 정보를 포함합니다.
- Version : BIP(Bitcoin Improvement Proposal)이라는 이름으로 여러 개의 Bitcoin 시스템의 향상을 위한 제안들이 존재합니다. 이를 통해서 실제로 Block의 Version이 바뀌기도 합니다. 그런데, 이것이 이전 Version의 Block과 호환이 된다면, 이를 Soft Fork라고 하고, 이전 Version과 호환되지 않는 독립적인 Chain으로 분리되는 것을 Hard Fork라고 부릅니다.
- Previous Block : Blockchain이라고 불리는 이유라고 볼 수 있습니다. 이전에 보았던 Transaction 처럼 Block 역시 이전 Block과 연결되어 있습니다. 이를 통해서 모든 거래 장부의 조회가 가능합니다.
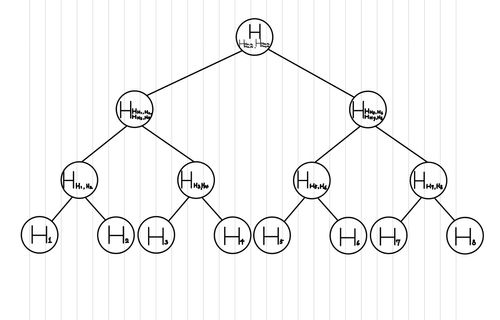
- Merkle root : 해당 Block이 소유하고 있는 Transaction의 hash값을 기반으로 만든 트리 구조에서 root에 해당하는 값입니다. 이는 후에 Block 내부에 Transaction 여부를 확인하기 위한 도구로 사용합니다.
- Timestamp : 해당 Block의 생성 시점을 의미합니다.
- Bits : 앞으로 나올 PoW part에서 다루는 내용으로, 이는 특정 작업의 난이도를 표현합니다.
- Nonce : 앞으로 나올 PoW part에서 다루는 내용으로, 이는 특정 작업에서 사용하는 변수값에 해당합니다.
1-1-5. Proof of Work(PoW)
이는 Blockchain에서 최초로 만들어진 개념은 아닙니다. 기존에 Spam mail을 막기 위한 수단으로 사용된 적이 있는 기술입니다. 이 기술의 목적은 무분별한 가짜, 사기, 무의미한 데이터가 빈번하게 네트워크 상에서 공유되는 걸 막는 것입니다. 즉, 누군가 악의적으로 Bitcoin 시스템을 마비시키기 위해서, 악의적으로 데이터를 무차별적으로 보내면, Block의 Transaction을 증명하는 데에만 너무 많은 자원을 소모하게 될 수도 있습니다. 따라서, 이를 막기 위해서 만들어진 것이 PoW입니다.
하나의 Block을 만들고, 공유하고, 검증받기 위해서는 반드시 어떤 특정 목표값에 해당하는 값을 찾도록 하여 이러한 무분별한 Block의 생성을 막도록 하는 것입니다. Bitcoin에서는 하나의 Block을 만드는 데 걸리는 시간을 평균 10분이 될 수 있도록 계속해서, 난이도를 수정하는 Algorithm을 갖고 있습니다. (2016 Block 단위로 난이도는 갱신됩니다.)
이제 여기서 궁금할 수 있는 사항이 몇 개 생길 수 있습니다. 이에 대해서 한 번 준비해보았습니다.
- 어떻게 평균 10분이 걸리는 문제를 낼 수 있는가?
hash 함수 중 hash256(sha-1 라는 hash 함수를 두 번 연속으로 수행하는 방법)을 사용하면, 이를 수행할 수 있습니다. sha 함수는 결과 값으로 나온 데이터의 각 자리가 1을 가질 확률이 1/2이라고 할 수 있습니다. 또한, 역연산을 통해서 찾을 수도 없기 때문에, 연속해서 0이 n개 나오는 값을 찾으라고 했을 때, 무작정 수행을 반복하면서 찾을 수밖에 없습니다. 이를 한 번 수행하는 데 걸리는 시간을 Block에 담긴 timestamp를 기반으로 계산하여 평균상 10분이 나오도록 값을 조정해준다면, 이것이 가능합니다. 이때 우리가 Block header에서 nonce라는 값을 계속해서 바꿔주고, 이를 포함한 Block header를 hash 하여 연속해서 0이 n개 나오도록 하는 nonce값을 찾게 된다면, 이것이 바로 하나의 Block이 되는 것입니다. - 난이도라는 것은 어떻게 변경되는 것일까?
Computer의 성능은 실시간으로 계속해서 발전하고 있습니다. 그렇기에 Block을 하나 채굴하는데 걸리는 시간은 계속해서 짧아질 것이라고 추측할 수 있지만, Bitcoin 시스템에서는 이 난이도 값을 bits라는 Block의 header를 통해서 통제할 수 있습니다. - Block에 담긴 Transaction은 어디에서 오는가?
Block에 담기는 Transaction은 모두 채굴자(Block을 생성하고자 하는 자)가 송금한 기록이 아닌 주변 node들로부터 전달받은 Transaction이 대부분입니다. 채굴자는 이를 Block에 담을 수 있는 양만큼 모아서 Block Header를 작성한 후, nonce라는 값을 찾아 떠나는 것입니다. 이때 Block에 담기는 Transaction의 우선순위는 Block을 만드는 이에게 달려 있습니다. - Block을 왜 만들어주는가?
아까도 말했듯이 Coinbase Transaction은 채굴자(Block을 생성하고자 하는 자)에게 향하는 output을 가집니다. 그렇기에 채굴자는 이를 통해서 Bitcoin을 벌 수 있는 것입니다. 또한, Transaction을 Block에 올리기 위해서, 주변 node들에게 Bitcoin 송금자들이 이를 요청하면서, 수수료 일부를 해당 node에게 가는 output으로 지정하기 때문에, Block을 만든다는 것은 Bitcoin을 버는 것과 같은 행위로 볼 수 있습니다. 또한, 올라갈 Transaction의 우선순위는 이 수수료에 기반하여 생성됩니다. - Block을 중간에 누가 바꿔서 자신의 것이라고, 바꾸면 어떻게 되는가?
최초로 발견한 Block에 대해서 누군가 이것을 자신이 발견했다고, 속이는 것은 의미가 없습니다. 애초에 Block을 도용하는 것은 이것을 통해서 발생하는 수수료를 일부 취하겠다는 것인데, 이는 Block 내부의 Transaction을 바꾸어야 하고, 이를 바꾼다는 것은 header의 merkle root 값을 바꾸는 결과를 초래합니다. 그렇게 되면 당연히 이전의 nonce값이 가지는 효과는 모두 사라지기 때문에, 도용한다는 것 자체가 불가능합니다. - Block의 검증은 어떻게 이루어지는가?
위에서 보았듯이 Block을 만들기 위해서는 앞에서부터 연속해서 0이 n개 나오게 하는 Block의 hash값을 찾아야 합니다. 하지만, 우리가 해당 Block을 받고, 이를 hash 한 후에 비교를 통해서, 이 Block이 적절한지 파악하는 것은 단 한 번의 hash로 가능합니다. 그렇기 때문에, 검증은 매우 쉽지만, 생성은 굉장히 어렵게 되는 것입니다. - nonce field의 크기가 정해져있던데 모든 nonce를 모두 사용했는데도 찾을 수 없다면 어떻게 되나요?
이때에는 coinbase transaction의 값을 살짝 조정합니다. 이를 조정하게 되면, merkle root의 값도 변경되기 때문에, hash를 다시 수행할 수 있습니다. - BlockChain에 동시에 여러 Node가 등록을 하게 되면 어떻게 되는가?
일단 Block을 만들게 되면, 해당 채굴자는 이를 전파합니다. 이것이 올바른지를 파악한 다른 Node들은 이를 자신의 Blockchain에 연결하게 되고, 똑같이 전파하기를 반복합니다. 이렇게 다른 모든 Node들이 해당 Block을 포함하는 Blockchain을 갖게 되면, 해당 Block은 이제 타당하다고 할 수 있습니다. 그렇지만 동시에 여러 Block을 받은 경우에는 해당 Block을 여러 개 모두 병렬로 연결해두고 있다가, 가장 먼저 새로운 Block이 연결된 Block을 채택하고, 나머지 기존 Block은 버리게 됩니다. 그렇기에 Block을 채굴했다고 끝인 게 아니라 완전히 선택되기까지는 완벽하게 Bitcoin을 획득했다고는 볼 수 없습니다. 그렇기에 대개의 경우에는 자신을 포함한 Block이 6개 연결되었을 때, 비로소 해당 Block이 Blockchain에 완벽하게 등록되었다고 보는 것이 일반적입니다.
1-1-6. Genesis Block
Block 내에서도 최초의 Transaction이 존재하듯이, Block 또한, 최초의 Block이 존재합니다. 이를 우리는 Genesis Block이라고 부르고, 모든 Block의 최상단은 해당 Block이 됩니다. 해당 Block의 Coinbase Transaction의 ScriptSig에는 Bitcoin의 창시자 Satoshi의 동기가 담긴 문구를 포함시켰다.
(chancellor on brink of second bailout for banks)
1-2. P2P network
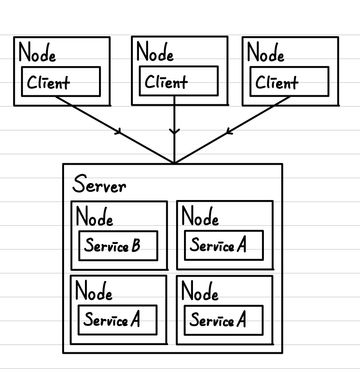
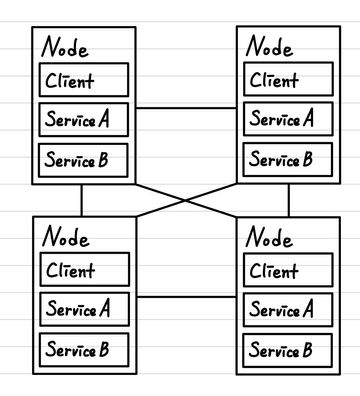
우리가 생각하는 Internet과 게임 산업과 각종 서비스들은 대게 큰 규모의 Server를 가지고 있는 업체가 자신들의 서비스를 해당 Server를 통해서 모든 Client(사용자)들에게 제공하는 형태를 띄고 있습니다. 즉, 소프트웨어 개발자가 소프트웨어를 제공함과 동시에 소프트웨어 사용자가 통신하여 얻을 데이터들도 모두 소프트웨어 개발자가 관리한다는 특징이 있습니다. 이것이 대게 일반적인 형태의 서비스입니다. 하지만, 이와 전혀 다른 구조를 가지고 있는 것이 P2P network입니다. 이는 Peer to Peer의 줄임말로, 각 Client(사용자) 간의 연결을 통해서 Service를 제공한다는 점이 매우 특이한 점입니다. 즉, 개발자는 Software를 만들고, 이를 배포하는 역할만을 하고, Software 끼리의 통신은 Server를 통해서 수행되는 것이 아닌 각 Software끼리 연결되어 하나의 거대한 통신 network를 만드는 형식입니다. 이렇게 만든 네트워크는 Software만 무결하게 만들었다면, 서로가 서로를 검증하고, 주체적으로 판단할 수 있는 환경을 만들어서 더 건전한 네트워크 환경을 만들 수도 있습니다. 기존의 Server 구조에서는 모든 Client의 요청을 Server에서 해결하기 때문에, 부담이 매우 크고, 해킹의 타깃이 되는 등 하나의 시스템에 대한 부하가 굉장히 크다는 단점이 있습니다. 하지만, P2P 구조에서는 이러한 부담을 나눠가지기 때문에 오히려 안전해질 수 있다고 볼 수 있습니다.
그래서, Bitcoin에서는 Block을 공개하기 위한 P2P network를 사용합니다. 중앙에 있는 시스템 없이 개인이 언제든지 모든 Blockchain을 보관하고 있을 수 있고, 이를 이용해서 특정 거래에 대하여 검증을 하는 등의 작업을 수행할 수 있도록 합니다. 그렇기에 서로가 서로를 감시하며, 서로가 보내는 데이터에 대한 100%의 신뢰를 갖지 않고, 직접 검증을 통해서 다시 한 번 확인하도록 하는 것입니다. 이것이 Bitcoin에서 추구하는 탈중앙화 된 거래 관리 방식이라고 할 수 있습니다.
1-3. Blockchain Data Types
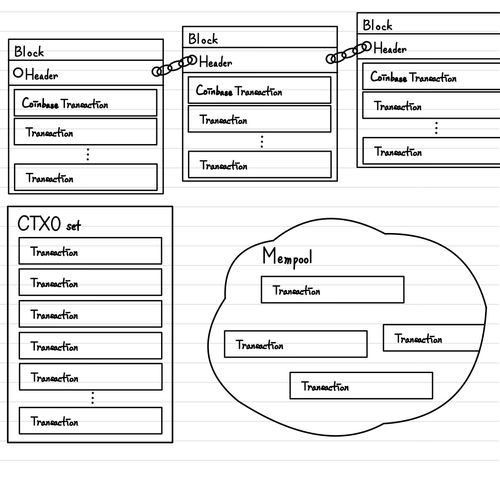
P2P network를 통해서 Block과 Transaction이 공유가 되기 때문에, Bitcoin 시스템 내에서는 데이터를 다음과 같이 3가지로 나누어 보관합니다.
- mempool : 승인되지 않은 Transaction을 보관하는 pool입니다. miner들은 이를 Block에 담아서 P2P network로 다시 공유하고, 이를 받은 node는 이를 Blockchain에 연결시켜서 Block을 만들어냅니다.
- Blockchain : Block을 하나의 긴 chain의 형태로 보관하는 것입니다. 이는 모든 Bitcoin 거래에 해당하는 가계부(원장)이라고 할 수 있습니다.
- UTXO set : 이전에도 살펴보았지만, 우리는 Transaction의 검증을 수행할 때 반드시 해당 Transaction의 사용여부를 확인할 필요가 있습니다. 따라서, 해당 Transaction 중에서 사용되지 않은 Transaction Output을 Blockchain에서부터 추출하여 별도로 저장하는 것입니다. 이를 통해서, 전체 Blockchain을 조회하는 것보다 빠르게 사용하지 않은 Transaction output을 찾을 수 있습니다.
1-4. Blockchain Node Types
P2P network에서는 여러 개의 node가 존재할 수 있습니다. 어떤 Node에서는 Block 자체를 생성해내는 역할을 할 수도 있고, 어떤 Node에서는 최소한의 Transaction 만을 가지는 경우도 존재합니다. 이에 대해서, 알아보도록 합시다.
- Full Node
- Miner Node
- Light Node
1-5. Block 내의 Transaction의 존재 여부
Block 내의 Transaction의 여부를 파악하기 위해서는 간단히 Block에서 Transaction을 찾아서 조회하는 것이 가장 간편합니다. 하지만, 이것이 불가능한 경우가 있습니다. 바로, 모든 Blockchain을 담을 수가 없는 경우입니다. 2022년 현재를 기점으로 Blockchain의 데이터 사이즈는 400GB를 넘어섰습니다. 이를 Smartphone과 같은 장치에서 모두 보관하는 것은 불가능합니다. 따라서, 이를 좀 더 간소화할 수 있는 방법을 찾는 과정에서 만들어진 것이 Header의 Merkle Root입니다. 이것의 원리를 알기 위해서 Merkle Tree에서부터 알아보아야 합니다.
2. Merkle Tree
2-1. 배경
Blockchain의 뭐든 Block을 갖고 있는 것은 어떤 Node에게는 굉장히 큰 부담이 될 수 있습니다. 따라서, 우리가 이를 보관함으로써 하고자 했던 행동으로 관심을 돌린 것입니다. 원래 목적인 Block 내의 Transaction의 존재 여부를 확인하는 것이 목표였기 때문에, 이를 모두 유지할 필요는 없습니다. 그래서, 이에 대한 요약본을 가지는 것이 바로 Merkle Tree입니다.
2-2. 정의
MerkleTree는 Proof of Inclusion(포함 여부를 증명)하기 위해 고안된 data structure(자료구조)입니다. 이름에서부터 느낄 수 있겠지만, 구조는 Tree 형태를 갖고 있습니다. 또한, 이는 두 개의 핵심 개념에 의해서 구현됩니다.
- Ordered List
- Hash Function
구조화하는 방법은 매우 간단합니다.
- Ordered List를 leaf 노드 갯수로 갖는 complete binary tree(leaf node를 제외하고는 모든 node가 채워져 있으며, 왼쪽에서부터 데이터가 채워지는 형태입니다.)를 만드는 것이 목표이므로, 모든 Ordered List를 포함할 수 있는 leaf node를 가지는 complete binary tree를 생성합니다.
- 이제 leaf노드에 각 ordered list의 element들을 hash function을 적용하여, 채워넣습니다.
- 이제 각 leaf 노드에서부터 차근차근 위로 올라가면서, tree 구조의 모든 node의 값을 채울 것입니다. 여기서 parent의 값은 left node의 hash 값과 right node의 hash값을 이어 붙여서(더하는 것이 아니라 이어서 붙입니다.) 다시 한번 hash function을 적용하는 식으로 구합니다.
- 여기서, 만약 왼쪽 node는 있지만, 오른쪽 node가 없는 경우, 왼쪽 node를 복사하여 오른쪽 node에 붙여 넣습니다.
- 이 과정을 반복하면서, root 노드에 있는 값까지 구해냅니다.
이렇게 만들어진 것이 merkle tree입니다. 이 구조가 왜 포함 증명을 하기에 적합한지를 알아보도록 하겠습니다.
2-3. 동작원리
라는 Transaction이 Merkle Tree의 포함되어있는지를 확인하기 위해서 다음과 같은 방식으로 사용될 수 있습니다. Light Node가 Blockchain에서 Transaction의 존재 여부를 확인하고자 할 때 다음과 같은 연산을 수행할 수 있습니다. 먼저, 근처의 Full Node에게 Flag Bit와 Hash 값을 요청하는 것입니다. 그리고, 이를 이용해서, 정말 가 포함되었는지를 확인할 수 있습니다. Flag Bit와 보낼 Hash 데이터는 다음과 같이 선정됩니다.
- 먼저 Merkle Tree를 위해서 설명한 대로 제작하고 이를 보관합니다.
- 그리고 해당 Transaction Hash 값에 해당하는 Block에서 해당 Transaction Hash를 찾습니다. 아래에서는 노란색입니다.
- 그렇다면, 만약 우리가 파란색으로 표시된 데이터만 있다면, 보라색 값을 유추할 수 있다고 할 수 있습니다.
- 또한, 우리는 Merkle Root 값을 갖고 있기 때문에, 이를 통해 유추해낸 Merkle Root값과 Merkle Root이 같다면, 해당 Transaction이 해당 Block에 있다는 것은 증명되었다고 할 수 있습니다.
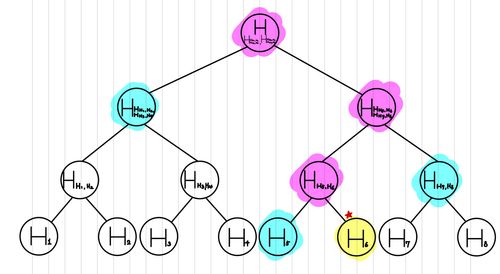
따라서, 우리가 가지고 있어야 할 데이터는 우리가 보낸 파란색 hash의 값과 위치를 유추할 수 있는 값만 있으면 됩니다.
따라서, 우리는 다음과 같은 형태로 이 과정을 수행합니다.
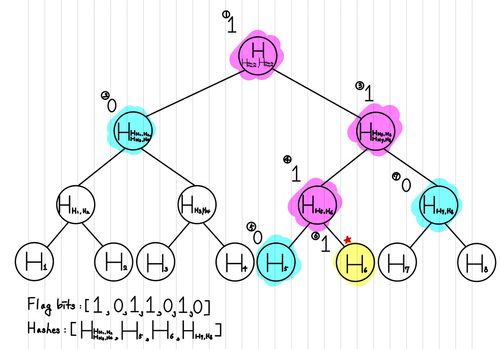
이제 Flag Bits와 Hashes만을 갖고 있으면, 이제 우리는 이를 역연 산하는 것도 가능합니다.
3. BloomFilter
3-1. 배경
Blockchain의 기반은 뿌리 깊은 불신에서부터 시작됩니다. 여기서, 이전에, 내가 가지고 있는 Transaction에 대해서 조회하는 것은 자신의 자산을 노출하는 것이 될 수도 있습니다. 따라서, 자신의 자신을 감추기 위해서 사용하는 것이 Bloom Filter입니다. Bloom Filter는 완벽하게 감추는 것은 아니지만, 다른 데이터와 중첩되도록 하여 쉽게 추측할 수 없도록 하는 데 있습니다.
3-2. 정의
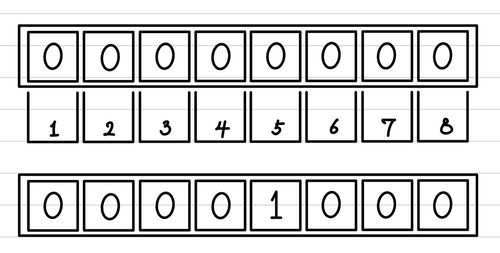
Bloom Filter란 데이터를 hash 하고, 이를 Bit field라는 영역으로 나누어 담는 것입니다. 나누어 담은 데이터는 1개의 Bucket이라는 영역에 담기게 됩니다. 이때 Bucket은 하나의 Bit가 될 수도 있고, 여러 개의 Bits가 될 수도 있습니다. 또한, 동일한 Bucket에 담기는 데이터의 양은 평균적으로 "\text{# of data} \div \text{# of bucket}"가 됩니다.
여러 개의 Bits를 하나의 Bucket으로 쓰는 경우에는, 다음과 같이 많은 양의 Bucket이 만들어질 수 있습니다.
3-3. 동작원리
먼저, 데이터를 hash 하여 임의의 값을 생성해냅니다. 그리고 해당 값을 Bit Field의 크기로 modulo 연산(%)을 수행해주어 나온 결과를 넣어주면 됩니다. 만약, Bucket의 크기를 1 이상으로 하고 싶다면, 다른 hash 함수를 수행하거나 다시 한번 연산을 수행하여 만들도록 합니다.
4. SegWit
4-1. 배경
먼저 거래의 양이 급격히 증가하면, Block에 담을 수 있는 Transaction의 양을 늘리는 것에 대한 토의가 빈번했습니다. 이 상황에서 어떻게 하면 더 효율적인 Transaction의 저장을 할지에 대한 고민이 깊어졌습니다. 또한, Transaction의 ScriptSig Part는 ScriptPubKey와 결합하여 안정적인 결과만 내놓을 수 있으면 되기 때문에, Transaction의 ScriptSig는 하나의 고정된 데이터가 아닌 여러 다른 형태를 가질 수 있었습니다. 또한, 이를 바꾸게 되면, Transaction의 값을 Hash 하여 얻는 Transaction의 ID가 변경되기 때문에, 다른 Transaction으로 여기고 Bug가 발생하기도 하였습니다.
4-2. 정의
Segrete Witness의 줄임말로, Block에서 부터 서명 부분을 분리하는 것을 목표로 만들어졌습니다. 이렇게 하게 되면, 두 가지 장점을 가질 수 있습니다. 바로, 하나의 Block에 더 많은 Transaction을 포함할 수 있을 뿐만 아니라 서명 부분의 코드가 조금씩만 바뀌어도 Transaction ID가 바뀌어 혼란이 발생하는 Transaction Malleability 위협을 차단할 수 있다는 것입니다.
4-3. 동작원리*
바로 기존 ScriptSig 부분을 비워두는 것이 핵심입니다. 이를 통해서, 변화하지 않는 형태로 두고, 이전에 보았던 p2psh의 redeemScript처럼 후에 변환할 수 있는 ScriptSig를 별도로 저장하도록 하는 것입니다.
원리는 Simple 하지만, 여기서 기억해야 될 것은 SegWit가 Soft-fork를 통해서 구현될 수 있다는 점입니다. 즉, 이전에 SegWit를 사용하지 않는 Node들과도 호환이 된다는 점입니다. Soft-fork를 유지하기 위해서, 구조는 더 복잡해지고, 이해할 수 없는 형태가 될 수 있습니다. 하지만, 이것이 Bitcoin 시스템에서 호환성이 큰 문제가 될 수 있다는 것을 보여주는 아주 대표적인 예시이기 때문에 이를 알아두면 좋습니다.
이전 글과 동일하게 구현 사항은 github에 정의해두었습니다.
Reference
- 🔗 Programming Bitcoin
- Tumbnail : Photo by Icons8 Team on Unsplash

![[Bitcoin] 1. ECDSA를 이용한 서명](https://euidong.github.io/images/bitcoin.jpg?imwidth=640)
Comments