Intro
Ethereum의 TPS를 Client 단에서 향상 시키기 위한 노력으로, LMPT는 Layered Merkle Partical Trie의 약자이다. 이는 기존 Ethereum에서 사용하던 MPT의 성능 향상을 위하여 제기된 아이디어로 Computer Architecture에서 흔하게 사용되는 cache를 접목한 방법이다. (해당 논문 ICBC 2022의 논문 중 LMPT를 기반으로 한 요약글이다.)
Terms
- ERC-20
Ethereum과 호환이 가능한 token에 대한 표준을 제시한 문서이다. 즉, 이 표준을 만족하는 token은 Ethereum을 통해서 교환이 가능하며 그 반대도 가능하다. - Tether token
Tether token은 ERC-20에 기반한 대표적인 token으로, 미국 달러와 1:1로 대응하는 USDT로 유명하다. 실제 거래에서도 빈번히 사용되는 ERC-20 token이다. - Trie
Trie는 sequence로 이루어진 데이터의 빠른 검색을 위해서 만들어진 tree의 일종이다. 데이터를 저장할 때 sequence 데이터의 검색을 최적화하는 것을 목표로 한다. 원리는 다음과 같다. sequence의 검색 시에 sequence의 앞에서부터 맞는 node를 root에서부터 검색하며 찾아나간다. 이 덕분에 검색 시에는 sequence의 길이만큼의 시간이면 충분히 데이터를 찾는 것이 가능하다. 하지만, 저장 sequence를 풀어서 저장하는 방식이기 때문에 경우의 수가 엄청 많아진다. 이는 sequence를 하나의 데이터로 보는 것보다 저장 공간을 많이 차지한다는 단점도 있다. - Patricia Trie
Trie에서는 기본적으로 모든 sequence를 요소 하나를 node로 보았다면, Patricia Trie에서는 각 nnode가 두 개로 나뉘어진다. branch node, leaf node이다. leaf node는 각 sequence의 끝을 의미하며 각 sequence는 반드시 하나의 leaf node로 종결되어지고, branch node는 저장한 데이터 중에서 중복이 발생하는 경우 중간 지점으로 저장해두는 방식이다. 따라서, Trie에서는 각 노드가 sequence의 하나의 값을 의미했다면, Patricia Trie에서는 path가 sequence의 요소들을 의미한다. 이에 대한 이해를 위해서는 아래에 제시된 그림을 보는 것이 좋을 것이다.(좌. trie, 우. patricia trie)
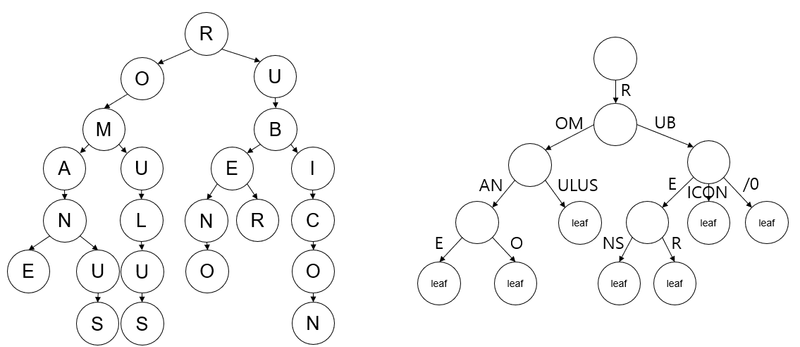
- Merkle Tree
Bitcoin에서 사용된 자료구조로 Blockchain의 모든 Block을 저장하는 것은 특정 node에게는 부담이 될 수 있기 때문에 이에 대한 인증을 쉽게 하기 위해서 요약본만을 저장하는 방식이다. 자세한 내용은 🔗 bitcoin-4의 2. Merkle Tree 부분에서 자세히 다루었다. 간단히 설명하자면, Block을 serialization하고 hash하여 결과값을 저장한 후 이를 leaf node로 하는 형태의 binary tree를 만드는 것이다. 그렇기에 우리는 Merkle Tree의 hash값 몇개만 갖고도 해당 transaction을 포함하는 block이 유효한지를 파악할 수 있다. - MPT
Merkle Patricia Trie의 줄임말로 기존 Bitcoin에서 사용하던 Merkle Tree와 Patricia Trie의 결합을 통해 만들어낸 자료구조이다. 이에 대한 설명은 아래에서 더 자세히 다룬다. - Latency bound issue
Memory에서 너무 많은 데이터를 얻어오려고 할 때를 의미하는 Memory Bound 중의 하나로 data를 Memory 만으로는 가져올 수 없을 때, secondary storage에서 불러오는데 발생하는 latency를 의미한다.
Problem
Bitcoin에서 시작된 Blockchain에 대한 응용은 의료, 공급망 관리 등으로 확장되며 계속해서 발전되고 있다. 그럼에도 불구하고 아직까지 transaction의 빠른 처리는 challenge한 부분으로 남아있다. 이는 P2P 환경에서 안전한 transaction의 생성 및 조회 그리고 검증을 위해서 어쩔 수 없는 trade off로 받아들여졌다. 그 결과 7~30 tps(transaction per second)정도에 그치는 성능을 보여주고 있다. 주류인 중앙 처리 방식은 수 천개의 transaction을 처리하는 것과 비교했을 때에는 굉장히 낮은 수준이다.
이를 해결하기 위해서 다년간 여러가지 접근 방식과 해결책이 제시되었다(AI-gorand, Conflux, Prism, OHIE, etc). 이를 통해서 수 천개의 transaction을 blockchain에서 처리하는 것이 가능하게 되었다. 하지만, 실제로 응용하는데에는 한계가 있었다. 그것은 state를 보관하는 ledger 단에서 발생하는 것이 아닌 실제로 transaction을 처리하는 client 단에서의 문제이다. 이는 바로 blockchain state를 변경하는 transaction이 빈번하게 발생하는 경우 client 단에서 새로운 bottleneck이 발생한다는 점이다. 실제로 가장 유명한 Ethereum Client인 GoEthereum과 OpenEtereum에서는 700 tps로 기존 제시된 수 천 transaction보다는 한참 못 미치는 성능을 보여준다.
그 원인은 사실상 state machine이라고 할 수 있는 Ethereum과 이것의 검증을 위해 제안된 MPT의 구조적인 한계로 인해 발생한다(이는 Background에서 제대로 다룰 것이다). 이 구조적인 한계에 의해서 다음과 같은 현상들이 발생한다.
- key-value 짝으로 이루어지는 데이터의 read/write 연산이 증폭해서 발생한다.
- 특히 write operation은 모든 node에 대한 hash를 재계산하도록 한다.
- 이러한 동작이 완료되기 전까지 반드시 transaction을 처리하는 thread는 대기해야 한다.
이를 해결하기 위해서, 해당 논문은 LMPT라는 새로운 자료구조를 제시한다. 이는 기존 Ethereum의 MPT를 기반으로 하는 시스템보다 6배 정도 상승된 tps 성능 지표를 보여주고 있다. 이것의 핵심 아이디어는 MPT를 계층화(layer)하는 것이다. 즉, 최근 update된 내용을 별도의 저장공간을 활용하여 저장해두고 이를 우선적으로 활용하기 때문에 더 빠른 처리 성능을 보여주는 것이다.
Background
1. Ethereum
Ethereum은 기존 Bitcoin Blockchain System과 확연히 다른점이 있다. 바로 State Machine이라는 점이다. 기존의 Bitcoin에서는 거래 내역을 모두 공개하고, 이를 통해서 우리는 최초 Block에서부터 이 거래 내역을 읽어들이면서 가진 자산을 확인할 수 있다. 즉, 거래 history를 종합해서 결과값을 얻는 것이다. Transaction의 수정과 삭제 없이 계속해서 추가만 이루어지는 형태라고 볼 수 있다. 하지만, Ethereum에서는 Transaction을 State Machine의 상태를 변화시키는 하나의 action으로 받아들인다. 따라서, Transaction에 의해서 우리는 상태가 변화하도록 하는 방식인 것이다. 따라서, 우리는 해당 State만 보고 자신의 자산을 파악할 수 있는 것이다.
2. MPT
결국 Ethereum 시스템을 활용하기 위해서는 모든 것이 공개되는 Network 상에서 안전하게 State와 이를 변경하는 Transaction을 보관하는 것이 중요하다. 이러한 data를 무결하게 그러면서도 수정, 삭제, 검색 등이 용이할 수 있도록 하기 위해서 Ethereum에서는 MPT(Merkle Patricia Trie)를 활용한다. 이는 결국 위에서 설명한 Merkle Tree와 마찬가지로 하위 Node의 Hash값을 상위 Node에서 가지기 때문에 Root Hash만을 비교하여 검증을 할 수 있다는 점에서 강점을 가지고 있다.
MPT는 3가지의 Node로 이루어진다.
- Leaf Node
실제로 value를 저장하는 말단 node이다. 만약, path로 key가 모두 표시되지 않았다면, key-end에 남은 key를 모두 담는다. - Extension Node
Leaf Node 이외에 경로의 확장이 필요할 때 사용되어지는 Node로 Branch Node의 hash data를 하나로 합치는 등의 역할을 한다. - Branch Node
16개의 pointer를 포함하는 Node로 이를 통해서 Leaf, Extension, Branch Node를 가르키는 데 사용할 수 있다.
따라서, 일반적인 구조는 아래와 같다.
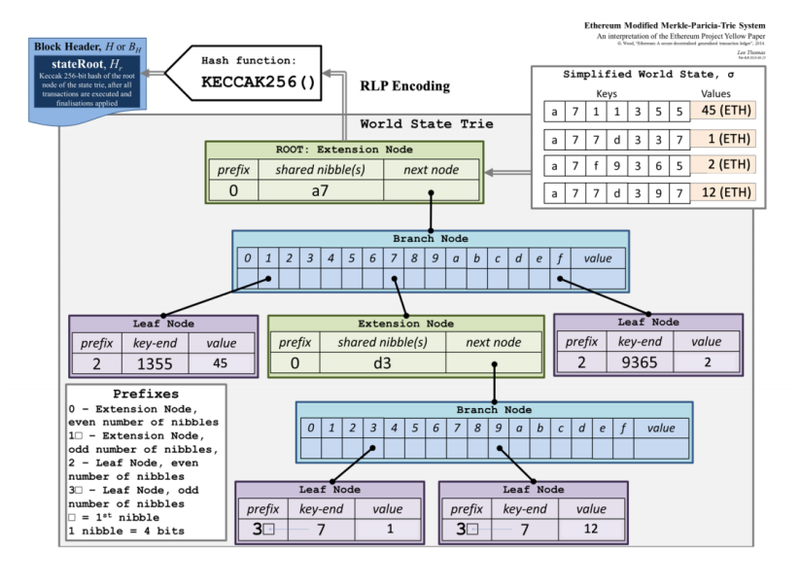
이 구조가 가지는 의의는 결국 우리는 하위 node들을 hash한 데이터를 상위 node에서 포함하고 있기 때문에 필요에 따라 trie에 일부분만을 저장해도 data의 검증은 충분히 가능하다는 점이다. 따라서, 모든 data를 가지는 full node와 달리 light client는 더 적은 데이터만 갖고도 검증이 가능한 것이다. 하지만, light client에서 authenticated read(full node의 도움이 필요한 read)를 수행하고자 하는 경우 full node에서는 read를 수행하기 위해서 path를 따라서 읽기를 반복해나가며, leaf node에 있는 최종 value를 얻어와야 한다.
3. Further Observation
해당 논문에서는 OpenEthereum Client를 관측하고, 기존 논문들에서 여러 영감을 얻었다. 다음은 이 논문에서 insight를 얻는 데 중요한 역할을 한 관측 정보이다.
-
Transaction이 Blockchain State에 빈번하게 접근할 수록 Transaction의 처리 성능은 낮아진다.
-
실제 Transaction의 실행 시간 중에서 가장 많은 시간을 차지하는 것은 Blockchain State에 접근하는 동작(SLOAD, SSTORE)이다.
🔗 기반 논문(Securing Smart Contract with Runtime Validation) -
한 번의 Transaction은 여러 번의 IO을 유발한다.(IO amplication)
MPT 구조에서 하나의 key 조회를 위해서 한 번에 데이터를 찾을 수 없기 때문에 결국 key를 통해서 Trie를 순회하여야 한다.
이는 key에 대응되는 Node가 많을 수록 많은 IO를 요구한다. -
Transaction 실행 thread는 병렬적으로 실행되지 않고, 위에서 제시된 operation이 끝날 때까지 대기한다.
즉, Transaction을 처리하는 Thread는 critical path(section)를 지키기 위해서 단 하나만 존재한다는 것이다. -
memory cache size를 늘리는 것은 성능향상에 큰 도움이 되지 않는다.
Memory Cache size(MB) Hit Rate TPS 50 0.635 1238 100 0.758 1256 500 0.862 1278 1000 0.879 1292 위의 표를 보면 알 수 있지만, Cache Size를 늘렸을 때 Hit Rate는 늘릴 수 있지만 TPS의 성능 향상 폭은 5% 수준에 그친다. 이는 memory cache를 제대로 사용하지 못하고 있음을 의미한다.
즉, 해당 논문에서는 하나의 Transaction에 의해서 IO가 빈번히 발생하는데 이를 병렬적으로 처리하는 것도 기존 MPT만으로는 한계가 있기 때문에 이를 해결할 수 있는 방법을 제시한다.
LMPT
Layered Merkle Patricia Trie의 약자로 기존 Ethereum MPT의 한계를 극복하기 위해서 제안하는 자료구조이다. 이의 핵심적인 목표는 Authenticated Ethereum State를 더 효과적으로 저장하는 것이다. 여기서 사용하는 핵심 아이디어는 바로 기존 Computer Architecture에서 사용했던 Hierarchical Memory의 구조를 그대로 차용하는 것이다. 즉, cache로 사용할 수 있는 MPT를 더 구현해두는 것이다. 이는 결론상으로 MPT의 read시에 IO amplication을 효과적으로 줄일 수 있다.
우선 구성 요소는 다음과 같다.
- Delta MPT
Read access가 요청되면 가장 먼저 조회되는 MPT이다. - Intermediate MPT
Delta MPT 이후에 조회되는 MPT이다. - Snapshot MPT
원본이라고 할 수 있는 MPT이다. 전체 blockchain data를 저장하며, disk에 존재한다. - Flat KV Store
read시에 가장 마지막에 조회된다. 이 역시도 전체 blockchain data를 저장하지만, 차이점이라면 key를 path로 하여 조회하는 MPT와 다르게 key, value store형태이다.
그렇기에 snapshot MPT와 동일하게 disk에 존재하지만, 더 빠르다게 조회가 가능하다는 장점이 있다.
snapshot MPT를 조회하는 대신에 이를 통해서 조회를 한다면, key를 통해서 바로 조회할 수 있는 방식이기 때문에 read IO amplication을 효과적으로 줄일 수 있다.
위의 까지는 read시에 최적화를 수행하였다면, write 시에는 이렇게 계층화를 해두었기 때문에 disk에 write하는 동안의 여유가 생길 수 있다. LMPT에서는 MPT의 적은 변화일 경우에는 delta MPT에 저장하고 있다가 periodic checkpoint를 두고, 해당 시점마다 delta MPT의 변경사항은 intermediate MPT, intermediate MPT의 변경 내용은 snapshot MPT에 합친다. 따라서, write 동작은 시간차를 두고 batch 단위로 verification과는 독립적으로 진행된다. 이는 결국 병렬적으로 IO 작업을 처리할 수 있는 여지를 만들어준다.
[Design] Structure
어떻게 실제로 이를 구현했는지에 대한 outline을 제시하면 다음과 같다. (OpenEthereum은 Rust를 이용하기 때문에 LMPT도 Rust에 기반한 code이다. psuedo code이기 때문에 해당 언어를 몰라도 알아볼 수 있을 것이다.)
1struct Trie { 2 root: uint256, 3 kv: Map 4} 5struct LMPT { 6 delta, interm: Trie, // In memory 7 snapshot: Trie, // In Disk 8 flat: Map // In Disk 9}
위에서 제시한 전체 구성요소와 마찬가지로 delta, intermedidate, snapshot mpt를 정의하고 flat를 정의한 것을 볼 수 있다.
[Design] Read/Write
실제로 Write와 Read는 아래와 같이 수행되어진다. 코드는 논문을 참조하였지만, 설명은 직접 작성하였다.
1T := LMPT() 2 3fn write_LMPT(k, v) { 4 root := T.delta.put(T.delta.root, k, v) // put new k, v data and get recomputed root hash 5 T.delta.root := root // set new root 6} 7 8fn read_LMPT(k, auth_proof) -> <v, p> { 9 // get value and path from delta mpt with key 10 <v, p1> := T.delta.get(T.delta.root, k) 11 // check whether value is exist or not 12 // if exist, then return value and path 13 // if not exist, then we get a adjacent path from delta MPT and store it in p1. 14 if v is present 15 return <v, p1> 16 // get value and path from intermediate mpt with key 17 <v, p2> := T.interm.get(T.interm.root, k) 18 // check whether value is exist or not 19 // if exist, then return value and path(p1 is adjacent path in delta, p2 is real path in intermediate MPT) 20 // if not exist, then we get a adjacent path from intermediate MPT and store it in p2. 21 if v is present 22 return <v, p1 + p2> 23 // if client want authneticated read(when they can't have authenticity), 24 // then request to snapshot MPT and return result 25 // else then request to flat kv store and return result without path. 26 if auth_proof 27 <v, p3> := T.snapshot.get(T.snapshot.root, k) 28 return <v, p1 + p2 + p3> 29 else 30 v := T.flat.get(k) 31 return <v, dummy> 32}
간단하게 요약하자면, 결국 write의 경우에는 다음 절차가 끝인 것이며,
- key, value를 받아서 delta MPT에 저장한다.
- 변경된 root hash를 delta MPT에 적용한다.
read의 경우에는 다음과 같은 절차가 끝인 것이다.
- delta MPT를 우선 조회한다.
- intermediate MPT를 다음으로 조회한다.
- 만약, 출처가 확실한 요청인 경우 auth_proof가 필요없으므로, flat KV store를 조회한다.
- auth_proof가 필요하다면, snapshot MPT를 조회한다.
[Design] Merge
write 과정에서는 delta MPT에만 추가를 수행했었다. 아래에서는 실제로 변경사항을 snapshot MPT와 flat KV store에 적용한 것이다.
1// merge intermediate MPT to snapshot MPT and flat KV store 2fn merge_compute(T) -> (root, flat) { 3 flat := T.flat 4 root := T.snapshot.root 5 for <k, v> in T.interm.kv(T.interm.root) 6 root := T.snapshot.append(root, k, v) 7 flat := flat.set(k, v) 8 return (root, flat) 9} 10 11// reconfigure flat, snapshot root, intermediate MPT, delta MPT 12fn merge_update(T, root, flat) { 13 T.flat := flat 14 T.snapshot.root := root 15 T.interm := T.delta 16 T.interm.root := T.delta.root 17 T.delta := Trie() 18 T.delta.root := None 19}
이 과정도 간단하게 요약하자면 다음과 같다.
- merge_compute, merge_update가 주기적으로 실행되도록 설정한다.
- merge_compute에서는 intermediate MPT의 data를 모두 snapshot MPT와 flat KV store에 추가한다.
- merge_update에서는 intermediate MPT는 이미 적용이 완료되었기 때문에 delta MPT를 intermediate MPT로 변경한 후, delta MPT를 비어 있는 MPT로 변경한다.
- 매 주기가 될 때마다 merge_compute와 merge_update가 순차적으로 실행된다.
위 method가 중요한 점은 바로 transaction의 write/read와 독립적으로 동작할 수 있다는 점이다. 즉, disk에 data를 write 하기 위해서 실제 transaction 처리에 waiting이 필요없다는 것이다.
[Design] Flush
위에서 제시한 Method를 다음과 같이 적용함으로서 다음과 같이 Ethereum state를 update하고, 무결하게 유지할 수 있다.
1block_cnt := 0 2merge_interval := 100 // you can set this constant 3 4T := LMPT(genesis_state) // setup initial state 5 6while Block is processing 7 for transaction in Block 8 T.update_trie(transaction) // apply transaction to LMPT 9 block_cnt += 1 10 if block_cnt % merge_interval == 0 11 Wait for last spawned thread to end // wait until previous thread finished. 12 merge_update(T, root, flat) 13 spawn_thread(root, flat=merge_compute(T)) // make new thread for merging
이 과정의 요약은 다음과 같다.
- merge_interval를 원하는 값으로 초기화한다. (이 값에 대해서 논문에서는 제시하지 않음)
- 초기 genesis_state를 통해 LMPT를 초기화한다.
- blockchain의 block을 처리하도록 한다. 새로운 block에 대한 처리도 이에 포함된다.
- 그 과정에서 특정 interval이 되면, 기존 merge_compute를 수행하는 thread가 있는지를 확인했다가 background로 merge_compute를 실행하는 thread를 생성한다.
Evaluation
본 논문에서는 평가를 위해서 다음과 같은 실험을 수행한다.
| data structure | workload | |
|---|---|---|
| Test1 | MPT vs LMPT | simple payment |
| Test2 | MPT vs LMPT | ETC-20 token (Tether) |
여기서 실험 시에 고려한 사항은 다음과 같다.
- 실제와 같은 상황을 만들기 위해서 실제 Ethereum transaction 500,000개를 활용한 benchmark를 만들었다.
- 또한, 또 다른 insight를 얻기 위해서 각 address간의 고르면서도 random하게 transaction을 보내도록 하는 Random senders traces benchmark도 만들었다.
- 또한, 간단한 payment의 경우와 복잡한 smart contract에 의해 동작하는 ETC-20 token 중 가장 많이 사용되는 Tether token을 활용한 비교도 수행하였다.
결과적으로 state로 보관해야할 account의 수가 많아질 수록 LMPT와 MPT 사이의 차이를 명확하게 볼 수 있는 형태를 보여준다. 이 차이는 더 복잡한 ETC-20 token에서 더 명확하게 들어나고 성능 차이는 적게는 1.2배에서 6배 이상까지도 벌어지는 것을 확인할 수 있다. 이를 통해서 결과적으로 cache를 활용하여 더 효율적인 Transaction 처리가 가능하다는 것이다.
Related Work
해당 논문은 결국 Blockchain의 MPT 구현을 변형하여 효율적인 방법을 제시하였다. 이외에도 TPS를 향상시키기 위한 여러 방법이 제시되었다. 하지만, LMPT는 이러한 연구들보다 앞 선 결과를 보여준다. 그 이유를 들기 위해서 다음과 같은 사전 연구와 비교했을 때 어느 점이 좋은지를 밝힌다.
- Distributed MPTs
LMPT와 가장 유사한 연구 사례들로 MPT의 구현을 변경하여 최적화를 하고자 한 사례이다. 하지만, 이들 중에서도 LMPT가 더 우수하다는 것을 다음을 통해서 알 수 있다.- 🔗 mLSM
MPT 자체를 여러 개의 MPT로 나누어 저장하는 방식을 택하였다. 이를 통해서 read, write 시에 IO amplication을 막을 수 있었지만, 오히려 write 시에는 여러 번의 중복 writing으로 인해서 더 많은 비용이 발생하였다. - 🔗 RainBlock
MPT를 sharding하여 분배하여 저장하는 방식을 선택하였다. 이를 통해서 성능을 올리는 것이 가능했지만, 이는 전체적인 Ethereum 구현을 바꾸어야 한다. 하지만, LMPT는 이러한 변경없이도 client단에서 쉽게 구현 및 변경이 가능하다.
- 🔗 mLSM
- Consensus protocols
consensus protocol을 변경하여 최적화를 하려는 시도 역시 많았다(HyperLedger Fabric, Prism, etc). 하지만, 이를 통해서 storage bottleneck을 해결할 수는 없다. 따라서, 해당 연구와 consensus protocol 관련 연구는 상호 보완적인 관계로, 같이 사용하게 되면 더 좋은 성능을 보일 것이라고 기대하고 있다. - Sharding in Blockchains
sharding은 Ethereum v2의 architecture 중 하나로 제시된 내용 중 하나로 이를 이용하게 되면 transaction 실행을 분산하는 효과를 불러올 수 있다. 하지만, shard간의 일관성을 유지하기 위한 protocol과 shard간 cross-shard 통신으로 인한 overhead도 고려해야 한다. 이러한 내용을 제쳐두고도 결국은 sharding과 LMPT는 독립적으로 동작할 수 있기 때문에 consensus protocol과 같이 독립적으로 보아도 무관하다.
Opinion
TPS를 향상 시키기 위한 방법은 Bitcoin이 처음 생기고 나서부터 계속해서 고려되고 있는 문제라고 생각한다. 해당 논문에서는 기존 논문이 였던 mLSM에서 영감을 얻어서 이를 더 발전시킨 방법을 찾았다고 생각한다. 단순히 여러 개의 MPT를 구현하는 것을 넘어서 실제 문제를 명확하게 정의해서 여러 개의 MPT로 어떻게 이를 해결할 수 있는지를 명확하게 제시한 것 같다. 여러 개의 MPT를 통해서 read 과정에서 locality를 확보했을 뿐만 아니라 merge 과정을 write 과정에서 분리함으로서 기존 transaction이 가지던 bottleneck을 해소한 것이다. 이 점이 명확하게 받아들여져서 해당 분야 전공이 아님에도 쉽게 이해할 수 있었다. 하지만, 아쉽게도 실제 구현 code를 찾을 수는 없었기에 flush단계에서 사용된 merge_interval의 정확한 값이 궁금했지만 찾지는 못했다. 또, 이 임계값이 상황에 따라서 성능에 큰 영향을 미치는 요소라고 파악을 하고 있었는데 이를 알 수 없어서 아쉬웠다.
아마 여기서 후속 연구를 진행할 수 있다면, 해당 임계값을 ML, DL, RL을 이용해서 좀 더 효과적으로 적용할 수 있는 방법을 찾아보는 것도 좋은 연구 방향이 될 수 있을 것이다. 이러한 주제를 처음 접했고, Ethereum의 구현에 대해서도 전혀 아는게 없었기 때문에 다양한 사전 조사를 요구했던 논문이였다. 하지만, Background에 대한 설명도 자세히 나와있고, Idea 자체가 명확했기에 훌륭하고 가독성이 높은 논문이 된 거 같다.
Reference
- Jemin Andrew Choi, Sidi Mohamed Beillahi, Peilun Li, Andreas Veneris, Fan Long
"LMPTs: Eliminating Storage Bottlenecks for Processing Blockchain Transactions", May 2022 - Ao Li, Jemin Andrew Choi, Fan Long
"Securing Smart Contract with Runtime Validation", June 2020 - Tumbnail : Photo by Shubham Dhage on Unsplash
- Merkle Patricia Image : https://ethereum.stackexchange.com/questions/268/ethereum-block-architecture
- Pandian Raju, Soujanya Ponnapalli, Evan Kaminsky, Gilad Oved, and Zachary Keener, University of Texas at Austin; Vijay Chidambaram, University of Texas at Austin and VMware Research; Ittai Abraham, VMware Research,
mLSM: Making Authenticated Storage Faster in Ethereum, July 2018 - Soujanya Ponnapalli, Aashaka Shah, and Souvik Banerjee, University of Texas at Austin; Dahlia Malkhi, Diem Association and Novi Financial; Amy Tai, VMware Research; Vijay Chidambaram, University of Texas at Austin and VMware Research; Michael Wei, VMware Research,
RainBlock: Faster Transaction Processing in Public Blockchains, July 2021
Comments