Intro
우리가 NL을 제대로 분석하기 위해서 각 단어가 가진 의미를 알아야하며, 이를 넘어서 문장이 가지는 의미를 파악해야 한다. 결론적으로 이 과정이 고도화된 NLP를 위한 핵심 단계이다. 이를 위해서는 Raw한 형태로 주어진 text를 처리해서 더 나은 형태의 구조를 만들 필요가 있다. 따지고 보면 하나의 전처리 과정이라고 볼 수 있다. 그치만 이전 text processing chapter과 다른 점은 문장 구분과 같은 간단한 과정이 아닌 Linguistic 단계에 따른 처리 과정을 수행한다고 볼 수 있다. 또한, 각 단계 역시 NLP 중에 하나라고 할 수 있으므로 이 또한 ML과 DL을 통해서 고도화하는 것도 가능하다. Morphology 단계부터 시작하여 Syntax, Semantic까지 어떻게 다루게 되는지를 살펴보도록 하겠다.
POS tagging
Morphology 단계에서 가장 기본이되는 요소이기 때문에 이를 먼저 살펴보도록 하겠다. Part of Speech라는 단어의 뜻 자체가 "품사"이다. 이는 단어의 문법적인 기능이나 형태 등을 표현하기 위해서 제시되었다. 이를 구분하려는 시도는 디오니소스 이전부터 있었지만 근본적인 형태를 제시한 것은 디오니소스가 첫 번째이다. 그는 기원전 100년에 지금과 굉장히 유사한 형태의 8개의 품사를 제시하였다. 지금도 8개지만, 감탄사와 형용사 등이 추가되고 몇몇 요소가 빠졌다. 이를 NLP 과정에서 input으로 활용하게 되면 언어의 모호성을 해결하는데 도움을 줄 수 있다. 품사를 통해서 단어가 가지는 뜻의 범위가 더 줄어들 수 있기 때문이다. 따라서, 이를 각 단어마다 표시하는 절차를 preprocessing으로 진행하는 경우도 많다.
우선 POS의 일반적인 종류는 다음과 같다.
- Noun(명사)
- Verb(동사)
- Adjective(형용사)
- Adverb(부사)
- Preposition(전치사)
- Conjunction(접속사)
- Pronoun(대명사)
- Interjection(감탄사)
하지만, Computer Science에서는 이를 좀 더 명확하게 표현하기 위해서 더 많은 분류(tag)를 사용하는 것이 일반적이다. 대표적인 예시가 🔗 Penn Treebank이다. 여기서는 36개의 종류를 활용하여 표기한다. 이외에도 Brown Corpus 등 다양한 tagging 방법이 있다. 또한, 언어에 따라서는 별도의 품사를 정의하는 경우도 많기 때문에 언어마다 적절한 방식을 사용해주는 것이 좋다.
tag를 정할 때 일반적인 규칙은 우리가 중/고등학교 시간에 배웠을 문법 요소를 적용한 것이 많다는 점을 기억하면 된다. NNS 같은 경우는 복수명사 뒤에 붙은 s를 포함하는 tag를 의미하고, VBD는 동사 과거형을 의미한다. 이와 같은 형태로 품사를 좀 더 세분화한 것 외에는 차이가 없다.
How can I get?
그렇다면, 어떻게 하면 POS tagging된 데이터를 얻을 수 있을지가 궁금할 것이다. 신기하게도 가장 쉬운 추론을 하더라도 90%의 정확도를 가질 수 있다. 다음과 같은 방법이다.
- 단어가 가지는 품사 중 가장 빈도가 높은 것을 표기한다.
- 못 본 단어인 경우 Noun(명사)로 표기한다.
이것이 가능한 이유는 사실상 대부분의 word는 모호하지 않다는 점이다. 대부분의 word는 품사 앞에서는 그렇게 변화무쌍하지 않다. 하지만, 특정 word는 사람 조차도 헷갈리는 경우가 있다. 대게 통계적으로 11%정도는 사람 조차도 헷갈릴 수 있는 형태의 품사가 주어진다고 한다. 그래서, 이를 해결하기 위해서 Statistic Inference를 활용하는 경우가 있고, 우리가 앞 서 배웠던 HMM을 활용하면 97%, MaxEnt를 활용하면 99% 정확도를 가지는 tagger를 만들 수 있다. 물론 더 복잡한 Deep Learning을 활용한다면 더 높은 성능도 가능은 할 것이다.
Morphology
Morphology 단계에서 POS tagging이 중요하긴 하지만 더 나아갈 필요가 있다. 결국 우리가 원하는 것은 단어의 의미를 더 완벽하게 찾는 것이다. 따라서, 대게의 경우 POS tagging을 포함하는 Morphology tagging을 수행한다. 특정 단어를 사전형 기본형(lemma) 또는 더 나아가 가장 뿌리가 되는 요소 root와 stem으로 나누고 여기에 품사를 덧붙이는 형태이다. 우리가 얻은 품사(tag)와 lemma만 갖고도 우리는 원래 단어를 만드는 것이 가능하고, 뜻의 범위를 더 한정할 수 있다. 더 나아가 root와 stem으로 나누게 되면 보지 못한 데이터에 대해서도 더 면밀한 의미 파악이 가능해진다. 이를 구현할 때에는 대게 4가지 방법 중에 하나를 수행하는 것이 일반적이다.
- Word form list
간단하게 생각하면, word list에서 단어를 조회하는 방식이다. 대게 key, value보다는 Trie 형태로 담는 것을 선호한다. Trie는 각 node가 sequence 데이터의 요소 하나하나가 되는 tree를 의미하며, sequence 데이터의 조회를 위해 사용된다. - Direct coding
root와 stem을 찾는 과정은 사실 영어에서는 간단하다. 앞 뒤에서 부터 진행하면서 대표적인 stem을 제거해 나가면, root만 남기 때문이다. 하지만, 일부 일본어와 같은 경우에는 이것이 불가능한 경우도 있다. 이 경우에는 다른 방식을 적용해야 한다. - Finite state machinery
각 단어의 형태를 FSM으로 정의하여 변할 수 있는 형태와 이에 따른 품사 등을 미리 표현하여 정의하는 방법이다. - CFG, DATR, Unification
언어학에 기반한 분석법이다.
사실 이러한 방법을 직접 구현하는 것은 한계가 있을 수 있다. 따라서, 이미 구현되어 있는 POS tagger를 사용하는 것이 현명할 수 있다. 일반적으로 가장 많이 사용되는 POS tagger는 다음과 같은 것들이 있다.
| Library | Language | ProgrammingLanguage |
|---|---|---|
| NLTK | English | Python |
| spaCy | English | Python |
| KoNLPy | 한글 | Python |
Syntactic Analysis
Morphology 단계에서는 각 word의 뜻을 다루었다면, 이 단계는 word의 결합으로 이루어지는 문장 구조를 분석하는 단계이다. 문장 구조를 분석(구문 분석)하는 방법은 크게 두 가지로 나뉘어진다.
- Phrase Structure
문장을 Phrase(구) 단위로 나누어 구조화 시키는 방법이다. 단어 각 각의 품사에서 부터 시작하여 이들을 묶어서 하나의 문장 요소(대게 phrase)를 만들어 하나의 문장을 만드는 구조를 가진다. - Dependency Structure
문장에서 각 단어가 가지는 의존 관계를 나타낸 구조이다.
각 구조는 둘다 Tree 형태로 이루어지며, 분석하는 방법도 서로 매우 다르다. 각 방법은 밑에서부터 자세히 다루도록 하겠다.
Phrase Structure
문장을 이루는 요소들과 요소들의 구조화 규칙을 정의해야 우리는 이를 분석할 수 있을 것이다. 따라서, 이를 정의한 것을 Grammar라고 한다. 그리고 이를 위해서 대표적으로 사용되는 것이 CFG이다. CFG는 Context Free Grammar의 약자로, 모든 잘 구조화된 문장들을 정의할 수 있는 규칙들을 의미한다. 각 각의 Rule은 왼쪽에는 문법적 type이 주어지고, 오른쪽에는 이를 이루는 요소들이 정의되어진다. 각 요소는 하위 문법적 type 또는 이전에 제시한 POS가 될 수 있다.
가장 기본적으로 사용되어지는 문법적 type들은 다음과 같다. 이외에도 기술하지 않은 POS도 사용이 가능하다.
| Symbol | Mean | Korean |
|---|---|---|
| NP | Noun Phrase | 명사 구 |
| VP | Verb Phrase | 동사 구 |
| S | Sentence | 문장 |
| DET(DT) | Determiner | 관사 |
| N | NOUN | 명사 |
| V | Verb | 동사 |
| PREP | Preposition | 전치사 |
| PP | Preposition Phrase | 전치사구 |
이에 따라 대표적인 Rule은 다음과 같다.
- S -> NP VP
- NP -> (DT) N
- NP -> N
- VP -> V (NP)
위에 제시된 Rule은 가장 기본적인 규칙으로 여기서 더 확장된 규칙을 만들어서 Parsing을 수행할 수 있다. 하지만, 이렇게 규칙을 만들어서 수행을 하게 되면 문제가 발생할 수 있다. 바로 여러 개의 Parsing Result가 만들어졌을 때 이 중에서 어떤 것이 가장 적절한지를 알 수 없다는 것이다. 즉, 너무 구체적인 Rule을 만들기에는 Parsing이 하나도 되지 않는 문장이 만들어질 가능성이 높고, 그렇다고 너무 적은 Rule을 적용하게 되면 Parsing이 너무 많이 만들어지게 된다.
따라서, 결론적으로 말하자면 위와 같은 형태의 CFG로는 phrase structure를 구조화하는데 한계가 있다는 결론을 내리게 된다. 결국 아래와 같은 두 개의 문제점에 직면하게 되고 이를 해결하기 위한 방법이 각 각 제시된다.
- Repeated work
문장 구조가 동일한 경우 결국 동일한 작업을 반복하게 된다. 이를 해결하기 위해서 Treebank라는 구조를 도입하고, 이것의 일부를 Dynamic Programming의 Memoization처럼 저장해두었다가 쓰는 방식을 적용한다. 즉, 기존에는 Rule만을 저장하고, 때에 따라 이를 적용하였다면, 이제는 모든 단어의 품사와 구조를 기록해두는 것이다. 이를 통해서 이미 나왔던 작업의 경우 빠른 처리가 가능해진다. - Choosing the correct parse
위에서 말했던 것처럼 우리는 결국 가장 적절할 거 같은 parsing result를 선택해야 한다. Rule에 기반한 방식으로는 한계가 있지만 우리가 Statistic한 방식을 활용한다면 이를 극복할 수 있다. 따라서, 우리는 CFG에서 나아가 PCFG(Probabilistic CFG)를 적용하여 이를 처리할 수 있다. 이러한 Statistical한 결과를 얻기 위해서도 Treebank 구조가 필요하다.
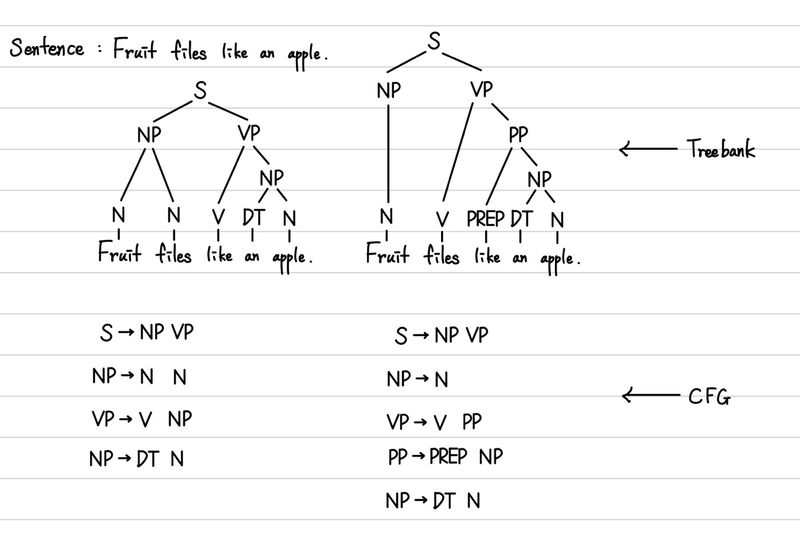
이제부터는 실제로 PCFG를 어떻게 수행할 수 있는지를 자세히 다뤄보도록 하겠다.
PCFG
앞 서 얘기한 것처럼 Probabilistic CFG로, 각 Rule마다 Probability를 적용하는 것이다. 여기서 유의할 것은 다음 내용이다.
- 기존 정의한 문법적 type을 만드는 Rule에 각 각의 확률을 정의한다.
- 이때 각 문법적 type을 만들 수 있는 Rule의 확률의 합은 반드시 1이다.
- 또한, 각 단어가 특정 POS일 확률도 같이 구해야 한다.
ex. N -> fish (0.5), V -> fish (0.1)
(실제로 이렇게 크게 나오지 않는다. N 또는 V 일 때, Fish일 확률이므로 굉장히 작은 값이 나오는 것이 일반적이다.)
따라서, 어떤 treebank가 더 적절한 지는 각 각의 treebank의 모든 Rule의 확률의 곱을 구해서 비교하면 된다. 굉장히 쉽게 이 과정이 가능한 것이다. 아래는 간단한 예시이다.
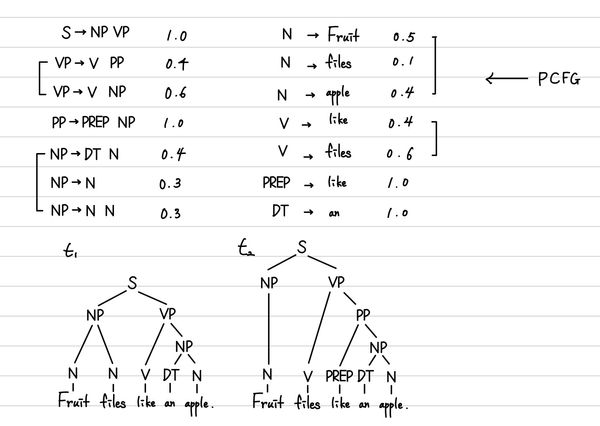
이렇게 주어졌을 때, 과 는 아래와 같이 구할 수 있다.
따라서, 형태가 더 적절하다고 판별할 수 있는 것이다.
1 🤔 Chomsky Normal Form 2 3 기존 CFG의 형태의 모호함을 제거하고, 좀 더 명확한 형태로 정의하는 것을 의미한다. 4 대표적으로 모호한 내용이 Sentence안에 Sentence를 포함하는 경우(n-ary)라든지, 5 명령문과 같은 문장을 위한 주어 삭제(unary/empty) 등이 존재한다. 6 이를 해결하기 위한 recursive 형태나 empty 형태 등을 제거하는 것을 의미한다. 7 8 결론상 PCFG에서는 확률 표기시에 모호한 표기를 제거할 수 있다는 장점이 있다.
CKY Parsing
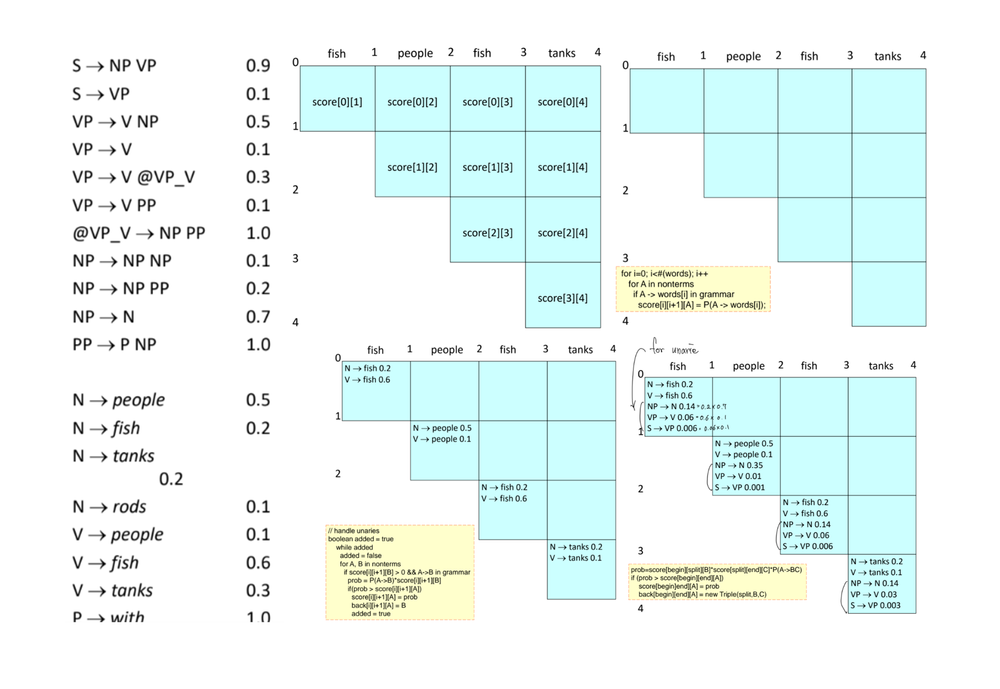
앞 서 우리가 treebank 중에서 더 큰 확률곱 값을 가지는 것이 최적값이라는 것을 알 수 있었다. 하지만, 사실 이 과정이 그렇게 쉽지는 않다. 왜냐하면, 우리가 가지는 Parsing Result는 굉장히 많을 수도 있기 때문이다. 그렇다면, 이를 연산하는 비용이 굉장히 비싸진다. 이를 효과적으로 연산하기 위한 알고리즘으로 제시된 것이 CKY Parsing이다.
Pseudo code는 다음과 같다.
1function CKY(words, grammar) returns [scores, backpointers] 2 // score[i][j] = 3 // 모든 Symbol(문법적 type, ex. S, NP, VP)에 대하여 4 // i부터 j까지 word를 사용했을 때의 최댓값을 저장 5 score = new double[#(words) + 1][#(words)+1][#(Symbol)] 6 // back[i][j] = 7 // 모든 Symbol(문법적 type, ex. S, NP, VP)에 대하여 8 // i부터 j까지 word를 사용했을 때의 최댓값을 만드는 요소의 위치를 저장 9 // (=back pointer) 10 back = new Pair[#(words)+1][#(words)+1][#(Symbol)] 11 for (i=0; i < #(words); i++) 12 // 초기화 단계로 각 단어가 Symbol일 확률을 입력 13 for (A in Symbol) 14 if A -> words[i] in grammar 15 score[i][i+1][A] = P(A -> words[i]) 16 // unary 즉 생략되어서 표현되는 경우를 위해서 확률 재계산 17 // ex. Stop!! (S->VP,VP->V) 18 boolean added = true 19 while (added) 20 added = false 21 for A, B in Symbol 22 if score[i][i+1][B] > 0 && A -> B in grammar 23 prob = p(A -> B) * score[i][i+1][B] 24 if prob > score[i][i+1][A] 25 score[i][i+1][A] = prob 26 back[i][i+1][A] = B 27 added = true 28 for (span = 2 to #(words)) 29 for (begin = 0 to #(words) - span) 30 // 일반적인 두 항의 합으로 이루어지는 경우를 계산 31 end = begin + span 32 for (split = begin + 1 to end-1) 33 for (A, B, C in Symbol) 34 prob = score[begin][split][B] * score[split][end][C]*P(A -> B C) 35 if prob > score[begin][end][A] 36 score[begin][end][A] = prob 37 back[begin][end][A] = new Triple(split, B, C) 38 // unary인 경우를 고려해서 재계산 39 boolean added = true 40 while (added) 41 added = false 42 for (A, B in Symbol) 43 prob = P(A -> B) * score[begin][end][B] 44 if prob > score[begin][end][A] 45 score[begin][end][A] = prob 46 back[begin][end][A] = B 47 added = true 48 return score, back
전체적인 동작과정은 그림을 통해서 이해할 수 있다. 먼저초기 score 할당부터 첫 단계에 데이터를 저장하기까지는 아래 그림으로 이해할 수 있다. 각 그림을 다음을 의미한다.
- score를 위한 공간 할당
- score에 가장 기본이 되는 Symbol -> word 확률 입력
- unari case를 확인해서 확률 입력
그 다음 단계로는 단계적으로 관계를 적립한다.
- 같은 형광펜으로 칠해진 데이터간 관계가 최댓값을 가진다.
- unari case도 확인한 결과 S->VP가 초기화 된다.
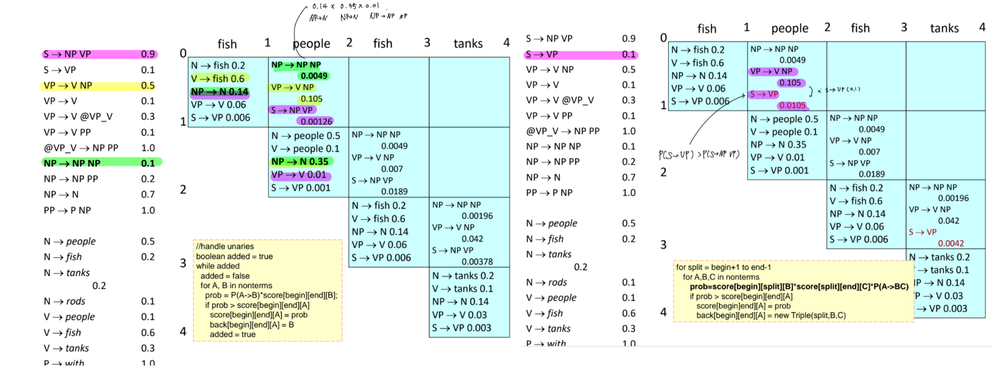
마지막에서 다시 관계를 정리할 때, 유의할 점이 있다. 바로 score[0][3]와 score[1][4]도 중요하지만 score[0][2]와 score[2][4]에 의한 관계도 반드시 유의해서 보아야 한다.

modeling
원래라면, modeling 단계도 다루어야하지만, 해당 단계에서는 넘어가도록 한다. 이를 수행하기 위해서는 간단하게는 단순히 빈도를 확인하는 것부터 EM algorithm을 활용하여 업데이트 하는 방식이 있다. 하지만 여기서는 자세히 다루지 않겠다.
Dependency Structure
문장에서 각 단어의 의존 관계를 나타내는 Dependency Structure는 중심 의미를 가지는 word로 부터 이에 의존하는 word들의 관계로 확장되며 표기된다. 따라서, 문장에서는 대게 동사가 중심이 되고, 그리고 그 다음으로는 전치사, 명사 등이 뒤를 잇게 된다. 이를 파악하게 되면, 단어가 연관성과 전체적인 구조의 안정성 등을 파악하는데 도움을 줄 수 있다.
이 형태를 얻기 위해서 할 수 있는 대표적인 방법은 다음과 같은 방법이 있다.
- Dynamic Programming
아주 쉽게 생각할 수 있는 방법으로 PCFG를 활용하는 것이다. 일반적으로 PCFG를 활용하여 tree 형태를 구축하면 이를 이용하여 Dependency Structure를 쉽게 구할 수 있다. 단순히 tree의 아래서 부터 의존 관계를 가진 단어를 고르면서 root까지 올라오면 이것으로 충분하다. 하지만, 이 과정은 시간적 비용이 많이 든다는 단점이 있다. - Graph Algorithm
가장 정확도가 높은 방식으로 Sentence에 대한 Minimum Spanning Tree를 구성하고, 이를 활용하여 ML classifier를 제작하여 구현할 수 있다. 가장 높은 정확도를 원한다면 해당 방식을 활용하는 경우가 많다. - Constraint Satisfaction
모든 경우의 수를 만들고 거기서 제한사항을 만족하지 않는 구조를 제거하는 방식이다. 이 또한 많이 사용되지는 않는다. - Deterministic Parsing
Greedy algorithm에 기반하여 구현된 방식으로 매우 높지는 않지만 적절한 정확도에 빠른 속도를 가지기 때문에 많이 사용되어진다.
Malt Parser
여기서는 Deterministic Parsing 중에서 가장 쉬운 방법 중에 하나인 Malt Parser를 좀 더 다뤄보도록 하겠다.
이는 3개의 자료 구조와 4개의 action을 통해서 정의되는 알고리즘이다.
먼저 자료구조는 다음과 같다.
- stack()
dependency tree의 상위 요소를 저장해두는 공간으로, 처음에는 ROOT라는 요소를 갖고 시작한다. - buffer()
input sequence를 저장하는 공간으로, 처음에는 input sequence를 전체를 저장하고 있다. - arcs()
최종으로 만들고자 하는 dependency tree를 의미한다. 처음에는 비어 있는 상태로 시작한다.
action은 다음과 같다.
- Reduce
stack()에서 word를 pop한다. - Shift
buffer()에서 stack()으로 word를 push한다. 이때 문장의 앞의 단어부터 차례대로 전달한다. - Left-Arc
stack()의 현재 word가 buffer()의 다음 word에 의존하는 경우, 이 관계를 연결하여 arcs()에 저장한다.
결론상 stack()에서는 pop이 되고, buffer()는 그대로 유지되며, arcs()에는 depdendency가 하나 추가된다. - Right-Arc
buffer()에서 다음 word를 stack()에 push하고, 기존 stack()의 이전 word에 의존하는 관계를 arcs()에 추가한다. - Finish
buffer()에 더 이상 word가 없다면, 모든 연산을 마무리할 수 있다.
이 또한 예시를 통해서 알아보는 것이 명확하다.
우리가 Happy children like to play with their friends.를 분석하고 싶다고 하자. 그렇다면, 절차는 다음과 같이 진행된다.
| Index | Action | Stack() | Buffer() | Arcs() |
|---|---|---|---|---|
| 0 | [ROOT] | [Happy, children, ...] | ||
| 1 | Shift | [ROOT, Happy] | [children, like, ...] | |
| 2 | LA(amod) | [ROOT] | [children, like, ...] | {amod(children, happy) = } |
| 3 | Shift | [ROOT, children] | [like, to, ...] | |
| 4 | LA(nsubj) | [ROOT] | [like, to, ...] | {nsubj(like, children)} = |
| 5 | RA(root) | [ROOT, like] | [to, play, ...] | {root(ROOT, like)} = |
| 6 | Shift | [ROOT, like, to] | [play, with, ...] | |
| 7 | LA(aux) | [ROOT, like] | [play, with, ...] | {aux(play, to)} = |
| 8 | RA(xcomp) | [ROOT, like, play] | [with, their,...] | {xcomp(like, play)} = |
| 9 | RA(prep) | [ROOT, like, play, with] | [their, friends, .] | {prep(play, with)} = |
| 10 | Shift | [ROOT, like, play, with, their] | [friends, .] | |
| 11 | LA(poss) | [ROOT, like, play, with] | [friends, .] | {poss(friends, their)} = |
| 12 | RA(pobj) | [ROOT, like, play, with, friends] | [.] | {pobj(with, friends)} = |
| 13 | Reduce | [ROOT, like, play, with] | [.] | |
| 14 | Reduce | [ROOT, like, play] | [.] | |
| 15 | Reduce | [ROOT, like] | [.] | |
| 16 | RA(punc) | [ROOT, like, .] | [] | {punc(like, .)} = |
| 17 | Finish | [ROOT, like, .] | [] |
자 이런 예시를 보았다면, 당연히 궁금해할 것은 어떻게 Action을 고를 것인가이다. 이는 Discriminative classifier 즉, Maxent나 여타 Machine Learning 방법을 동원하여 결정한다. PCFG를 활용하는 방식보다는 성능이 약간 낮을지라도 이를 활용하면 매우 빠르게 parsing이 가능하다는 장점이 있다.
1 🤔 Projectivity 2 3 사실 여태까지 우리는 연속되어 있는 word간의 의존성을 파악하는 과정을 살펴보았다.(특히 PCFG) 4 하지만, 그렇지 않은 경우도 분명히 존재한다. 대표적인 예시가 아래이다. 5 Who did Bill buy the coffee from yesterday? 6 여기서 from은 Who와 관계가 있지만, 우리가 여태까지 살펴본 PCFG와 Malt Parser로 7 이 관계를 밝히는데에는 한계가 있다. 8 따라서, 이를 해결하기 위해서 후처리나 추가적인 action을 Malt Parser에 더하거나 9 아니면 아예 다른 방식을 앙상블하여 해결하기도 한다.
Semantics
자세히 여기서 다루지 않지만, 구문 분석을 통해 얻은 Tree를 통해서 어떻게 의미를 추출할 수 있는지를 알아보겠다. 먼저, 우리는 전체 요소를 다시 한 번 두 가지로 나눈다.
- Entities
특정 의미를 가지는 하나의 주체이다. 주로 NP가 모두 여기에 속한다. - Functions
Entity 또는 다른 Function에게 동작, 특성, 등을 적용한다. 형용사, 동사 등이 여기에 속한다.
따라서, 우리가 Every nation wants George to love Laura.라는 문장을 갖고 있다면, 우리는 아래와 같이 Tree를 그릴 수 있고, 이를 이용해서 의미 분석이 가능하다.

위 Tree를 아래에서부터 연결해서 나가면 다음과 같이 구조화되는 것을 알 수 있다.
| Index | Expression |
|---|---|
| 1 | love(x, Laura) |
| 2 | love(x, Laura) |
| 3 | love(George, Laura) |
| 4 | want(x, love(George, Laura)) |
| 5 | present(want(x, love(George, Laura))) |
| 6 | Every(nation) |
| 7 | present(want(Every(nation), love(George, Laura))) |
| 8 | assert(present(want(Every(nation), love(George, Laura)))) |
Reference
- Tumbnail : Photo by David Ballew on Unsplash
- Penn Treebank POS tagging, https://www.ling.upenn.edu/courses/Fall_2003/ling001/penn_treebank_pos.html
- spaCy, https://spacy.io/
- NLTK, https://www.nltk.org/
- KoNLPy, https://konlpy.org/ko/latest/index.html
- NLP CFG, https://tildesites.bowdoin.edu/~allen/nlp/nlp1.html


![[NLP] 1. Linguistics](https://euidong.github.io/images/nlp-thumbnail.jpg?imwidth=640)
Comments