Intro
Natural Language(자연어, 사람이 사용하는 통상 언어)를 input으로 활용하고자 하는 노력은 컴퓨터의 등장부터 시작하여 여러 번 시도되어 왔다. 지금까지도 완벽하게 이를 처리하는 것은 힘들다. 왜 Natural Language를 다루는 것은 어렵고, 이를 해결하기 위해서 NLP에서는 어떤 방식을 활용할지에 대한 개략적인 overview를 제시한다. 또한, Natural Language의 특성과 분석 단계를 이해하기 위해서 Linguistics(언어학)을 간략하게 정리한다.
NLP
Natural Language Processing의 약자로 사람이 사용하는 언어를 input으로 하여 원하는 값을 추출해내는 것이 목표이다. 이를 위해서 우리는 사람의 언어를 이해하거나 다룰 수 있는 능력을 컴퓨터에게 부여해야 한다.
먼저, 이러한 필요가 있는 대표적인 usecase를 살펴보면 다음과 같다.
Usecase
- Spam Detection
가장 간단한 예시로 mail에서 spam 여부를 확인하는 기능이다. - POS tagging / NER
특정 단어 단위의 처리를 수행하게 되는데 단어의 품사와 대략적인 의미를 가진 category로 분류로 tagging하는 과정이다. 이를 기반으로 하여 다른 usecase에서 활용하는 경우가 많다. 품사와 category는 단어의 뜻을 추론하는데 큰 도움을 주며, 이것이 문장의 이해 등에 도움을 주기 때문이다. - Sentiment Analysis
감정/여론 분석 등의 영역을 의미하며, 텍스트 또는 대화에서의 긍정/부정 여부를 판단하거나 평점 등을 추출하는 기능이다. - Conference Resolution
"he", "she" 등 대명사, 생략 단어 등을 원래의 단어로 대체하거나 채우는 과정을 수행한다. 이 역시도 여러 영역에서 이를 기반으로 추가적인 작업을 할 수 있다. - Word Sense Disambiguation(WSD)
특정 단어가 주어졌을 때, 동의어, 동음이의어 등에서 가르키는 진짜 의미를 헷갈리지 않게 명확하게 다시 한 번 처리한다. 이 역시도 다른 NLP usecase에서 두루 사용된다. - Parsing
문장에서 단어들을 의미를 가지는 단위(구, 절, 문장)로 다시 grouping한다. 이 과정을 잘 수행하기 위해서는 이전 단계에서 WSD와 Conference Resolution, POS tagging, NER이 이루어지면 좋다. 이 과정을 통해서 문장의 개략적인 의미를 파악할 수 있다. - Machine Translation(MT)
특정 언어를 또 다른 Natural Language로 변경하는 기능이다. - Information Extraction(IE)
특정 문장에서 사용자에게 의미있을만한 데이터를 추출하는 것이다. - Q&A
특정 사용자가 질문을 하였을 때, 이 뜻을 이해하고, 이에 적절한 대답을 수행하는 방식이다. - Paraphrase
문장의 뜻을 이해하고, 더 쉬운 형태의 표현으로 변환하는 기능이다. - Summarization
여러 문장으로 이루어진 글의 의미를 이해하고, 적절한 내용으로 요약하는 기능이다. - Dialog
Natural Language를 사용하는 사람과 1:1로 담화를 주고 받는 것이다. 의미를 이해할 뿐만 아니라 자신이 내보낼 output에 대해서도 적절하게 생성할 수 있는 능력이 필요하다.
위와 같이 많은 usecase가 있는데 이를 구현하는 것은 지금까지도 굉장히 challenge한 부분이다. 그것은 Natural Language가 가지는 몇몇 특징 때문이다.
Why is NLP difficult?
여기서는 Natural Language 중에서 영어를 기반으로 한 설명이지만, 한국어도 매우 유사하다.
- non-standard : Natural Language를 사용하는 사람들이 표준을 항상 따르지는 않는다는 것이다. 우리는 약어를 사용하거나 문법에 맞지 않는 비문을 사용하여 의사소통을 하기 때문에 이것을 시스템이 이해하게 하는 것은 어렵다.
- segmentation issues : 의미를 가지는 단어 단위로 묶는 것이 어렵다는 것이다. 우리는 문장의 띄어쓰기를 어디로 받아들이냐에 따라서 의미가 달라지는 것을 본 경우가 있을 것이다.
- idioms : 관용구의 사용은 NLP에서 예외처리로 해주어야 하는 것이다. 단어 그대로의 의미와 다른 의미를 가지기 때문이다.
- neologisms : 신조어는 계속해서 생겨나기 때문에 이를 계속해서 업데이트 해주는 것도 부담이 된다.
- world knowledge : 사전 지식을 알고 있어야 이해할 수 있는 단어, 문장이 존재한다. 즉, 어떤 지식을 가지고 있느냐에 따라서 해석이 달라진다는 것이다.
- tricky entity names : 고유 명사 중에서 특히 contents(노래, 그림, 소설) 등의 제목이 해석 시에 헷갈리게 한다. 예를 들면, "Let it be"라는 비틀즈의 노래는 문장 중간에 들어가면, 하나의 문장으로 받아들여지게 되는데 이를 잘 해결할 수 있도록 해야 한다.
위의 내용을 요약하자면, 다양한 단어가 다양한 현상과 다양한 법칙(Grammer)의 영향을 받기에 어려우며, 단어가 가지는 모호성이 문제를 야기한다는 것이다.
Solutions
이러한 문제를 해결하기 위해서 크게 두 가지 방식을 사용할 수 있다.
- Rule based approach
Gammer와 같은 법칙을 모두 적용해서 prgoramming을 하는 것이다. 하지만, 이 방식은 비문과 같은 문장을 제대로 처리할 수 없을 뿐만 아니라 정확한 형태의 문장이라도 여러 의미로 해석되는 문장에서 경향성과 문맥을 전혀 파악할 수 없다. - Statistic based approach
그래서 최근에는 경향성과 문맥을 파악할 수 있도록 AI 기술, ML, Deep Learning을 이용하여 NLP를 수행하는 것이 하나의 trend로 자리 잡았다. 그렇다면, 어떻게 통계적인 접근법이 경향성과 문맥을 포함할 수 있을까? 이는 통계가 가지는 경향성이라는 특징과 conditional probability를 사용할 때의 문맥을 포함한 경향성을 파악할 수 있다는 점을 활용해서 가능하다.
Linguistics
결국 앞으로 통계적인 방식을 활용하더라도 우리는 최소한의 언어학적인 기본이 필요하다. 왜냐하면, 통계에 사용할 데이터를 처리하기 위해서이다. 우리가 사용할 데이터는 text 또는 음성이다. 이를 적절하게 처리하여 통계에 사용할 유의미한 데이터로 변환하는 과정이 필요하다. 이를 위해서 언어학에 대한 이해가 필요한 것이다.
일반적으로 언어를 분석할 때, 사용할 수 있는 도구는 Grammar이다. 이는 특정 language에서 허용되는 규칙의 집합을 정리한 것이다. 이것의 종류는 크게 두 가지로 나뉜다.
- Classic Grammar
사람이 실제로 언어를 사용함에 있어 발생하는 이상한 습관과 같은 언어 표현이다. 이러한 법칙들은 대게 예제들을 통해서 정의되는데 이런 것을 명확하게 구분할 수 있는 명백한 도구가 존재하지는 않는다. 예를 들면, 감탄사와 같은 것들이 여기에 포함되겠다. 이는 이러한 변칙적인 형태 때문에 programming적으로 표현하는 것이 불가능하다. - Explicit Grammar
명백하게 정의되어 있는 언어 규칙을 의미한다. 이는 Programm으로 구현할 수 있으며, 여러 Grammar 정리 내용이 이미 정리되어 있다. (CFG, LFG, GPSG, HPSG, ....)
이를 문법적으로 분석하기 위해서 우리는 6단계의 순차적인 처리가 필요하다.
6 Layers in Language
각 단계는 input과 output을 가진다. 단계적으로 진행되기 때문에 이전 단계의 output이 다음 단계의 input이 되며, 때때로 몇 단계는 생략될 수 있기에 유연하게 생각하도록 하자.
각 단계에서 실제로 특정 문장이 처리되는 과정을 이해하기 위해서 "Astronomers saw stars with telescope"라는 문장이 음성 또는 text로 들어왔을 때를 가정하여 각 단계에는 무엇을 하고 이를 통해서 어떻게 이 문장을 바꿀 수 있는지를 확인해보겠다.
1. Phonetics/Orthography(음성학/맞춤법)
먼저 Orthography는 맞춤법 검사를 의미하며, character sequence로 input이 들어오면, 이를 맞춤법에 맞는지를 확인하여 이것이 수정된 sequence로 반환한다.
예시 문장에 있는 "telescope"는 문법에 맞지 않으므로 "telescopes"로 바뀌어야 한다.
| input | output |
|---|---|
| Astronomers saw stars with telescope. | Astronomers saw stars with telescopes. |
Phonetics는 음성학을 의미하며, 혀와 음성의 영향을 주는 다양한 근육의 위치 형태, 모양, 빈도를 활용하여 자음과 모음을 분류하는 작업을 수행한다. Orthoography와는 달리 억양이라는 것을 추가적으로 활용할 수 있다.
| input | output |
|---|---|
| Astronomers saw stars with telescopes.를 의미하는 음성 신호 | əsˈtrɒnəməz sɔː stɑːz wɪð ˈtɛlɪskəʊps. |
*https://tophonetics.com/ 을 통해서 변환하여 얻을 수 있다.
2. Phonology/Lexicalization(음운론/어휘화)
Phonology은 음운론으로 소리와 phonemes(음소)사이의 관계를 이용하여, 음소를 특정 word로 변환하고, Lexicalization에서는 해당 단어를 사전에서의 형태로 변환하는 과정을 수행한다.
| input | output |
|---|---|
| əsˈtrɒnəməz sɔː stɑːz wɪð ˈtɛlɪskəʊps. | Astronomers saw stars with telescopes. |
3. Morphology(어형론)
Morphology는 어형론으로 음소의 구성을 기본형(lemma)의 형태로 변환하며, 각 단어들을 형태학적인 의미를 갖는 카테고리(category, tag)로 분류한다. 여기서 사용되는 lemma와 category가 무엇인지 좀 더 자세히 살펴보자.
- lemma
- 사전에 표기되는 단어의 기본형으로, 사전에서 word를 찾는 pointer가 된다.
- 동음이의어의 경우 특정 뜻을 지칭하고 싶은 경우에는 numbering을 수행하기도 한다.
- 더 나아가서는 형태소(morpeheme)까지 구분하기도 한다. 이는 혼자서 쓰일 수 있는 자립 형태소(root)와 의존 형태소(stem)으로 나눌 수 있다.
- 예를 들면, quotations -> quote[root] + -ation[stem] + -s[stem]
- 위와 같은 형태로 세분화할 수도 있지만, 대게는 lemma 단위에서 그친다.
- categorizing
- category는 정하기 나름이며, 이미 정해져있는 tagset들도(Brown, Penn, Multext) 많이 존재하고, 억양이나 실제 분류 등을 수행하는 것도 가능하다.
- POS tagging은 category를 분류하는 방법 중에서 가장 유명한데, 이는 여러 언어에서 거의 호환되기 때문에 이 방식을 활용하여 분석하는 것이 가장 안정적인 방법이라고 할 수 있다. 이는 별도의 Posting에서 더 자세히 다루도록 하겠다.
또한, 단어의 형태는 언어마다 다양하기 때문에 어느정도 언어마다 다른 작업을 해주어야 한다. 크게 구분되는 형태로 언어를 3개의 종류로 나눌 수 있다.
- Analytical Language(고립어)
하나의 단어가 대게 하나의 morpheme을 가진다. 따라서, 하나 이상의 category로 구분되어질 수 있다.
ex. English, Chinese, Italian - Inflective Fusional Language(굴절어)
prefix/suffix/infix가 모두 morpheme에 영향을 미치며, morpheme의 정의 자체가 애매해지는 언어 형태
ex. Czech, Russian, Polish, ... - Agglutinative Language(교착어)
하나의 단어에는 morpheme이 명확하게 구분되고, prefix/suffix/infix 또한 명확하게 구분 가능하다. 따라서, 각 morpheme에 명확한 category를 mapping하는 것이 가능하다.
ex. Korean, ...
| input | output(based on Brown tagset) |
|---|---|
| Astronomers saw stars with telescopes. | (astronomer/NNS) (see/VBD) (star/NNS) (with/IN) (telescope/NNS) (./.) |
4. Syntax(통사론)
lemma나 morpheme을 구문의 요소인 S(Subject, 주어), V(Verb, 동사), O(Object, 목적어)와 같은 요소로 분류한다. 이 분류를 수행할 때에는 문장의 구성요소를 알아야 한다. 이를 bottom-up으로 살펴보자.
- Word(단어)
사전에 명시된 하나의 단위라고 볼 수 있다. 이는 관용어(dark horse)를 포함한다. - Phrase(구)
둘 이상의 단어 또는 구의 결합으로 만들어진다. 대게 하나의 문법적인 의미로 변환되어진다.- 대표적인 예시
- Noun : a new book
- Adjective : brand new
- Adverbial : so much
- Prepositional : in a class
- Verb : catch a ball
- Elipse(생략)
대게 단어 또는 구가 생략되는 경우가 많다. 특히 담화의 경우 더욱 그렇다.
이를 추론을 통해서 추가할 수도 있다.
- 대표적인 예시
- Clause(절)
절은 주어와 서술어를 갖춘 하나의 문장과 유사하지만, 문장 요소로서 더 상위 문장에 속하는 경우이다.
또한, 영어에서는 특히 접속사로 연결된 절이 아닌 경우에는 해당 절이 지칭하는 대상이 절 내부에서 생략된다. 이를 gap이라고 한다. - Sentense
하나 이상의 절로 이루어지고, 영어에서는 시작 시에 대문자로 표기하며 종료 시에는 구분자로 .?!로 끝난다.
결국 우리는 이러한 요소를 적절하게 표시해야 하는데, 이를 위해서 tree 구조를 사용하는 것이 일반적이다. 대표적으로 두 가지의 구조가 있다.
- phrase structure(derivation tree)
문장을 기점으로 절, 구, 단어로 top-down으로 내려가는 구조를 가진다.
각 단위를 묶을 때에는 ()를 이용하고, 그 뒤애 해당하는 내용이 무슨 구, 절인지를 표기한다. - dependency structure
단어 간의 관계에 더 집중하여 나타낸다. 따라서, 사람이 보기에는 불명확해 보일 수 있지만 특정 usecase에서는 유용하다.
| input | output (phrase structure) |
|---|---|
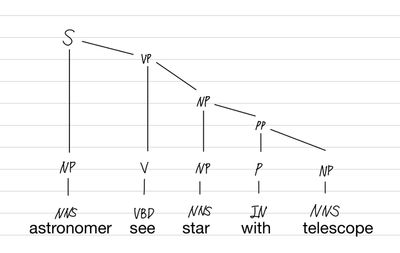
| (astronomer/NNS) (see/VBD) (star/NNS) (with/IN) (telescope/NNS) (./.) | ((astronomer/NNS)NP ((see/VBD)V ((star/NNS)NP ((with/IN)P (telescope/NNS)NP)PP)NP)VP)S |
5. Semantics(Meaning, 의미론)
간단하게는 주어, 목적어와 같은 tag나 "Agent"나 "Effect"와 같은 tag를 적용하며, 전체적인 의미를 유추해낸다.
| input | output |
|---|---|
| ((astronomer/NNS)NP ((see/VBD)V ((star/NNS)NP ((with/IN)P (telescope/NNS)NP)PP)NP)VP)S | ((astronomer/NNS)NP/agent ((see/VBD)V ((star/NNS)NP/affected ((with/IN)P (telescope/NNS)NP)PP)NP)VP)S |
6. Discourse/Pragmatics(담화/화용론)
실제 대화 등과 같은 목표를 해결하기 위해서 앞서 보았던 문장 구조를 이용한다.
만약, 해당 데이터를 통해서 하고자 하는 것이 이 이야기를 한 사람이 식당 내부에 있는지를 판단하고자 한다고 가정해보자.
| input | output |
|---|---|
| ((astronomer/NNS)NP/agent ((see/VBD)V ((star/NNS)NP/affected ((with/IN)P (telescope/NNS)NP)PP)NP)VP)S | False |
Reference
- Tumbnail : Photo by David Ballew on Unsplash
- text to phonetic converter, https://tophonetics.com


![[NLP] 2. Text Processing](https://euidong.github.io/images/nlp-thumbnail.jpg?imwidth=640)
Comments