Intro
NLP를 수행할 때, 우리는 sequence of character를 처리하는 방식을 제대로 알아야 제대로 된 전처리와 후처리 등이 가능하다. 따라서 해당 chapter에서는 어떻게 원본 문자/단어/문장을 처리하는 방식을 다룰 것이다.
Regular Express
아주 기본적인 문자열 처리 방법이다. 이를 알고 있어야 실질적인 처리가 가능하다. 해당 내용은 별도의 Posting으로 분리하여 다루었다. (🔗 Regex)를 살펴보도록 하자.
Text Normalization
우리가 사용할 NL은 정제되어 있지 않아서 여러 전처리를 수행해야 한다. 그 중에서 대중적으로 좋다고 알려진 방법들을 살펴볼 것이다. 기본적으로는 아래 단계를 처리하는 것이 일반적이다.
- Word Tokenization
말 그대로 NL 데이터가 입력되었을 때, 이를 단어 단위로 쪼개는 것이다. - Word Reformating
단어를 나누었다면, 각 단어의 형태를 처리하기 쉬운 형태로 Normalizing하는 것이다. - Sentence Segmentation
문장 단위로 구분해는 과정이다.
이제 각 단계를 세부적으로 다뤄보겠다.
1. Word Tokenization
우선 쉽게 생각할 수 있는 것은 단순히 띄어쓰기를 기준으로 구분하는 것이다. 그렇게 하면, 우리는 입력으로 주어진 Corpus에서 token을 추출할 수 있다.
하지만, "San Francisco"와 같은 단어가 두 개의 token으로 나누는 것이 아니라 하나의 token으로 처리되기를 원할 수 있다. 뿐만 아니라 일부 언어들(특히 중국어와 일본어)의 경우 띄어쓰기 없이 작성하는 언어들의 경우 문제는 더 커질 수 있다. 이 경우에는 Word Segmenting이라는 알고리즘을 활용할 수도 있는데, 원리는 매우 간단하다. 언어의 모든 단어를 포함하는 사전을 기반으로 문장에서 사전에 일치하는 가장 긴 문자열을 찾을 수 있을 때까지 token을 연장해서 만드는 방식이다.
그러나 이 방식도 결국은 특정 언어(중국어, 등)에서는 잘 작동하지만, 일부 언어(영어 등)에서는 잘 작동하지 않는 경우가 많다. 따라서, 최근에는 확률에 기반하여 같이 등장하는 횟수가 많을 경우 하나의 token으로 묶는 형태의 tokenization을 더 선호한다.
이 과정에서 우리가 추가적으로 수행하는 것이 바로 word의 갯수를 추출하는 것이다. 대게 우리가 관심 있어하는 수는 총 3가지이다.
- number of tokens
즉, 띄어쓰기로 나뉘어지는 token들의 총 갯수를 의미한다. - number of types(Vocabulary)
띄어쓰기로 나뉘어진 token들의 중복을 제거한 종류들의 갯수를 의미한다. 대게 이러한 type들의 모음을 Vocabulary라고 한다. - number of each type's tokens
각 종류의 token이 얼마나 많이 등장했는지를 의미한다.
여기서 이러한 token이나 type이 서로 같나는 것을 어떻게 구분할 수 있을까? 이를 위해서 Word Reformating을 수행하여 좀 더 일반적인 형태로 변형하여 위의 수들을 파악하기도 한다.
2. Word Normalization and Stemming(Word Reformating)
대게의 언어는 word의 형태가 여러 개로 존재한다. 이 과정에서 우리가 고려해야 할 것이 정말 많다. 그 중에서 가장 기본적으로 수행되어야 할 내용은 다음과 같다. 해당 내용은 영어에 중심을 둔 설명이다.
- Uppercase
영어에서 첫 글자는 대문자로 시작한다는 규칙이 있다. 또는 강조하고 싶은 단어를 대문자로 표현하기도 한다. 그 결과 token의 종류를 추출하는 과정에서 문제를 일으키기도 한다. 따라서, 이를 모두 lowercase로 바꿔버리는 것이다. 하지만, 모든 경우에 이를 적용할 수 잇는 것은 아니다. 가장 대표적인 예시로 US와 us의 의미가 다르다는 것이다. 또, 고유 명사인 General Motors와 같은 경우도 다르게 처리하는 것이 좋다. 따라서, 이를 고려해서 먼저 처리한 이후에 전체 데이터를 lowercase로 변환하는 방식을 수행한다. - Lemmatization
Lemma(기본형, 사전형)로 단어를 변환하는 것이다. 가장 기본적인 것은 am, are, is와 같은 be동사를 모두 be로 변환하거나 car, cars, car's를 모두 기본형태인 car로 바꾸는 것이다. 대게의 경우에는 이 과정에서 의미를 일부 잃어버리기 때문에 lemma + tag로 기존 token을 복구할 수 있도록 하는 tag를 포함하는 것이 좋다. - Stemming
morpheme(형태소)은 중심 의미를 가지는 stem과 핵심 의미는 아니지만 stem에 추가 의미를 더해주는 affixes로 나누어 word를 나눌 수 있다. 따라서, 각 token을 가장 core의 의미를 가지는 stem으로 나타내는 방식이다. 대표적인 예시가 automate, automatic, automation을 automat으로 변환하는 것이다. 이는 lemmatization보다 넓은 범위의 word를 하나로 묶기 때문에 세부의미가 더 손실될 수 있다. 따라서, 기존 의미로 복구할 수 있는 tag를 포함하는 것이 좋다.
3. Sentence Segmentation
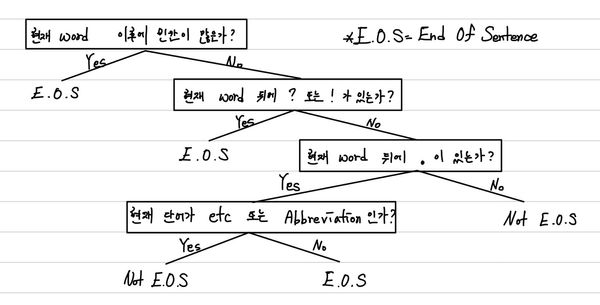
문장을 구분할 수 있는 도구로 우리는 "?", "!", "."을 활용한다. "?"와 "!" 같은 경우는 문장의 끝을 의미하는것이 대게 자명하다. 하지만, "."은 꽤나 애매할 수 있다. 소수점, Abbreviation(Mr., Dr., Inc.)와 같은 경우에 빈번하게 사용되기 때문이다. 따라서, 이를 판단하기 위해서 Decision Tree를 만들어서 이를 수행한다. 아래와 같이 사람이 직접 규칙을 정할 수도 있지만 현재는 대게 통계 기반으로 수행한다.
Collocation(연어) processing
Text Normalization을 통해서 우리는 sentence를 구분하고, word를 추출할 수 있었다. 하지만, 단순히 하나의 word를 기반으로 처리하는 것이 아니라 주변 단어를 활용하여 처리해야만 얻을 수 있는 정보들이 있다. 우리는 이를 Collocation(연어)를 활용하여 수행한다. 이는 특정 단어쌍이 높은 빈도로 같이 붙어 사용되는 현상을 말한다. "모든 단어는 이를 동반하는 주변 단어에 의해 특성 지어진다." 따라서, 우리는 이 collocation을 co-ocurrence로 생각할 수 있다. 이를 통해서 우리는 다음과 같은 것들을 할 수 있다.
- lexicography(사전 편찬) : 같가니 유사한 뜻을 가지는 단어는 빈번하게 붙어서 사용되는데 이를 이용해서 하나의 단어의 뜻을 안다면, 이를 통해서 다른 단어의 뜻을 추론하며 확장해나갈 수 있다.
- language modeling : NL를 통해서 원하는 결과를 얻기 위해서 특정 parameter를 추정해내는 것을 language modeling이라고 하는데 이 과정에서 collocation을 활용하는 것이 단일 단어를 활용하는 것보다 context를 활용할 수 있다는 점에서 장점을 발휘할 수 있다.
- NL generation : 우리는 문맥상 매끄러운 문장을 원한다. 즉, "감을 잡다"를 "감을 붙잡다"라고 했을 때, 뜻을 이해할 수는 있지만 어색하다고 느낀다. 따라서, 이 관계를 활용해서 NL을 생성해야 하기 때문에 collocation을 고려해야 한다.
그렇다면, 이러한 Collocation을 어떻게 찾을 수 있을까?
- Frequency
가장 간단하게 단순히 동시 발생 빈도를 확인하는 것이다. 정확한 파악을 위해서는 빈번하게 등장하는 의미 없는 단어를 먼저 filtering할 필요가 있다. 대표적인 예시로 a, the, and 등이 있다. - Hypothesis Testing
가설 검증으로 우리가 가정한 collocation을 지정하고, 이 사건이 일어날 가능성을 굉장히 낮게 하는 가설을 반대로 가정한 후에 이것이 불가능하다는 것을 증명하는 Null Hypothesis를 이용한 증명으로 타당성을 확보하는 것이다. 따라서, 우리가 보이고자 하는 것은 word1, word2가 있을 때, 두 단어가 서로 의존적이라는 것을 증명하고 싶은 것이다. 따라서, Null Hypothesis로 두 단어는 독립이다라고 지정하면, 우리는 다음 식을 얻을 수 있다.
이를 바탕으로 t-검증을 다음과 같이 수행할 수 있다.
t값이 이제 커질 수록 우리는 해당 가설이 틀렸음을 증명하여 collocation임을 주장할 수 있다.
Minimum Edit Distance
단어 또는 문장 간 유사도를 측정할 때, 사전을 기반으로 수행할 수도 있지만 참고할 corpus가 마땅하지 않거나 더 추가적인 수치가 필요하다면, Minimum Edit Distance로 유사도를 측정하기도 한다. 즉, 두 문자열이 같아지기 위해서 어느정도의 수정이 필요한지를 수치화한 것이다. 여기서 연산은 새로운 문자 추가, 삭제, 대체만 가능하다.
1S - N O W Y | - S N O W - Y 2S U N N - Y | S U N - - N Y 3distance : 3 | distance : 5
다음과 같이 표현이 가능하다.
-
문자열 x, y가 있을 때, 는 x의 0~i까지를 포함하는 문자열과 y의 0~j까지를 포함하는 문자열의 distance라고 하자.
-
이렇게 되면, 에서 우리는 끝문자의 규칙을 볼 수 있다.
오른쪽 끝 문자가 가질 수 있는 조합은 3가지 밖에 없다.
1x[i] | - | x[i] 2- | y[j] | y[j] 3distance: 1 | distance: 1 | distance: 0 or 1 -
그렇다면 우리는 하나의 사실을 알게 된다.
는 다음 경우의 수 중 하나여야만 한다.
-
따라서, 다음과 같은 식을 유도할 수 있다.
만약, 각 연산의 비용이 다를 경우라면, 1 대신에 그 값을 넣어주면 충분히 풀 수 있으며, 추가적으로 최적의 이동형태를 알고 싶다면, back pointer 하나를 추가하는 것으로 충분하다.
Reference
- Tumbnail : Photo by David Ballew on Unsplash


![[NLP] 1. Linguistics](https://euidong.github.io/images/nlp-thumbnail.jpg?imwidth=640)
Comments