Intro
컴퓨터를 사용할 때, 우리는 기본적으로 Memory가 무한한 크기를 가지고 있기를 바란다. 하지만, 이를 실제로 구현하는 것은 비용적으로도, 기술적으로도 불가능하다. 따라서, 이를 마치 존재하는 것처럼 느끼도록 하는 Virtual Memory라는 기술을 사용한다.
Locality
Virtual Memory를 위한 핵심은 Locality를 활용하는 것이다. 동작에는 인과가 존재하고, 그렇기에 직전에 자신이 했던 행동 그리고 근처의 대상들이 했던 행동이 지금의 자신이 할 행동에 영향을 주는 것은 어찌보면 당연한 사실이다. 이러한 특징이 Locality이다. 이를 이용해서 우리는 Memory를 마치 무한인 것처럼 느낄 수 있게 할 수 있다.
- Temporal Locality 하나의 Instruction 또는 data가 사용되었다면, 해당 내용은 곧 다시 사용될 확률이 매우 높다.(반복문일 경우에는 극명하게 드러날 것이다.)
- Spatial Locality 하나의 Instruction 또는 data가 사용되었다면, 후에 이 근처에 있는 내용을 사용할 확률이 매우 높다. (일반적으로 연속적으로 동작하는 경우가 많기 때문에 근처의 명령어들을 같이 가져올 수 있다면, 가져오는 것은 합리적이다.)
이를 활용하기 위해서, 우리는 Memory Hierarcy라는 방법을 사용한다. 즉, 메모리를 계층화하는 것이다. 모든 장치를 빠르고, 크고, 싸게 만들 수 있으면 좋겠지만, 실제로는 불가능하기에 빠르고, 작은 장치를 processor에 가까이에 두고, 그 보다는 덜 빠르고, 큰 장치를 좀 더 거리를 두고 위치시키는 방식이다. 이렇게 하면 이용자에게 싸면서, 빠른 시스템을 제공할 수 있다.
이를 위해서, 우리는 더 멀리 있는 Memory에서 정보를 복사해서 더 상위의 Memory에 붙여넣기하는 것이다. 계층 구조이기 때문에 한 번에 수행되는 것이 아니라 여러 단계가 있다면, 차근차근 순서에 맞춰서 수행된다. 즉, 단계를 skip하여 이동하는 것은 불가능하다.
만약, 상위 Memory 장치에서 원하는 정보(Block, Line)를 찾았다면 이를 hit라고 하고, 찾지 못했다면 이를 miss라고 한다. 또한, hit time은 상위 Memory가 해당 Block에 접근하는데 걸리는 시간을 의미한다. 반대로 miss penalty는 상위 Memory로 해당 Block을 위치시키는 시간과 Block을 processor에 전달하는 시간까지를 포함한다.
시작하기에 앞 서, 컴퓨터 공학을 공부하는 누구나 겪는 현상이라고 생각하는데 바로 Memory 파트는 언어가 매우 자기 멋대로 나오는 경향이 있다. 즉, 깔끔한 정리가 되지는 않았다. Memory가 어떨 때는 Main Memory를 의미하다가 전체 모든 저장 장치를 의미하기도 한다. 따라서, 이 아래부터는 다음과 같이 엄격하게 분리하여 설명한다.
- Memory : 모든 저장 장치들을 의미한다. 즉, cache, secondary storage, main memory 등을 모두 포함한 개념이다.
- Cache : Processor에 붙어서 바로 동작하는 Memory 장치
- Main Memory : 우리가 주로 RAM이라고 부르는 장치
- Secondary Storage : 주로 HDD, SSD로 이루어지는 보조 기억 장치
Memory Components
시작하기에 앞서 실제로 메모리를 이루는 구성요소들을 먼저 살펴보고 간다.
- DRAM(Dynamic Random Access Memory) Main Memory에 주로 사용되는 장치로 SRAM보다는 느리지만, 확실히 많은 데이터를 저장할 수 있다. 하나의 bit를 저장하기 위해서 1개의 transistor를 사용하는데, 이 transistor에서 전력이 새어 나가기 때문에 정보를 잃는 것을 막기 위해서 주기적으로 refresh를 해주어야 한다. Random Access라는 의미는 순차적으로 앞에서부터 탐색하는 방식이 아니고, 찾고자하는 데이터를 바로 찾을 수 있다는 의미이다. 따라서, 앞에서부터 찾는 방식보다 더 빠를 수 밖에 없다. 휘발성 저장 장치이기 때문에 전력이 공급되지 않으면 정보를 모두 잃는다.
- SRAM(Static Random Access Memory) Cache에 주로 사용되는 장치로 매우 빠른 연산이 가능하지만, 크기를 크게 만들기 위해서는 비용이 너무 비싸진다는 단점이 있다. 하나의 bit를 처리하기 위해서 6개의 transistor를 사용한다. 이 덕분에 전력을 다시 공급해주는 refresh 과정이 필요없다. 과거에는 processor 밖에서 chip 형태로 존재하였지만, 점점 회로가 집적이 되며, processor에 통합되었다. 휘발성 저장 장치이기 때문에 전력이 공급되지 않으면 정보를 모두 잃는다.
- Flash Memory Electrically Erasable Programmable Read-Only Memory(EEPROM)의 한 종류이다. 다른 장치들과는 달리 write가 flash memory를 닳게 만들 수 있다. 따라서, 대부분의 flash memory는 한 bit를 쓰기가 집중되는 현상을 막기 위해서, 이를 분산시키는 방식을 사용한다. (wear leveling, 쓰기 횟수에 제한이 존재한다.) 이는 대게 모바일 장치들의 저장 장치로 많이 사용되며, PC에서 사용하는 SSD와 매우 유사하다.
- Magnetic Disk 일명 자기 테이프 방식으로, 다른 장치들과는 다르게 자기력을 이용하여 정보를 저장하는 방식이다. 실제로 물리적으로 존재하는 Disk로 하여 Hard Disk라고도 부른다.이를 읽고 쓰기 위해서는 arm(팔)이라는 개체가 disk의 정보가 스여진 위치로 이동해야 읽을 수 있다. 따라서, 이것이 물리적으로 움직이는 시간이 소요되기 때문에 여타 Random Access 장비보다 느릴 수 밖에 없다. 하지만, 이를 통해서 저장할 수 있는 정보의 양은 매우 많다.
Cache
Main Memory와 Processor 사이에서 memory hierarchy를 수행하는 장치라고 한다. 하지만, 현대에는 이러한 구조에 영감을 받아서 cache를 여러 곳에서 사용하기 때문에, 많은 분야에서 이를 locality의 장점을 활용하기 위한 일종의 저장소라는 의미로 많이 사용한다.
Cache의 역할
Cache가 수행하는 역할은 저장 장치이기 때문에 읽기와 쓰기가 가능해야 한다.
Read
읽기를 수행하기 위해서 Cache에서는 다음과 같은 동작을 수행할 수 있어야 한다.
- Main Memory의 데이터를 일부 저장할 수 있어야 한다. Cache는 Main Memory보다 크기가 작기 때문에 Main Memory의 모든 데이터를 저장하지 못한다. 따라서, 일부분을 저장하는데 이를 저장할 때, 기존의 Main Memory에서의 데이터의 address를 cache의 크기만큼 나누어 cache의 범위에 들어오도록 하는 것이 Directed Mapping이다. 따라서, 다음과 같은 식이 성립한다.(여기서의 Block이란 한 번에 cache로 가져올 데이터의 단위를 의미한다.)
- 특정 word가 cache에 존재하는지 확인할 수 있어야 한다. 이를 위해서 우리는 tag를 이용한다. cache 공간으로 address가 변환되어서 생략된 address를 포함하고 있다. 즉, cache의 index로 쓰이지 않은 Main Memory Address의 상위값을 가지고 있다. 쉽게 생각해서 위에서 만들어진 Cache의 Block 주소가 나머지라면, tag는 몫이라고 볼 수 있다. 따라서, tag는 담기는 데이터에 따라서, 계속해서 변하여 저장되는 값이다.
- 해당 데이터가 타당한지 확인할 수 있어야 한다. 만약, system을 막 booting시켰다면, cache에는 모두 이상한 값이 들어갈 것이다. 따라서, 잘못된 값을 참조할 수도 있다. 따라서, 우리는 valid bit(1 bit)를 이용하여, 해당 값이 적절하게 할당한 값인지를 표기한다.
- 덮어 씌우기가 가능해야 한다. 이 경우는 간단히 덮어 씌어버린다. 이는 앞 서 설명한 temporal locality와 일맥상통한다. 최근에 쓴 데이터가 다시 호출할 확률이 높기 때문이다.
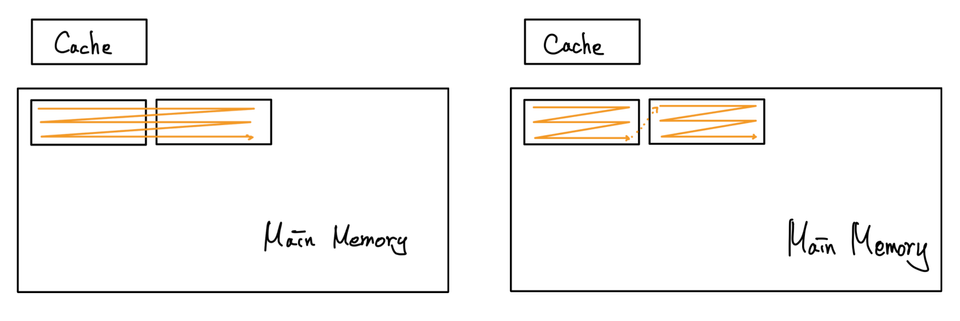
Example
왼쪽이 Cache고, 오른쪽이 Main Memory이다.
- 초기 상태
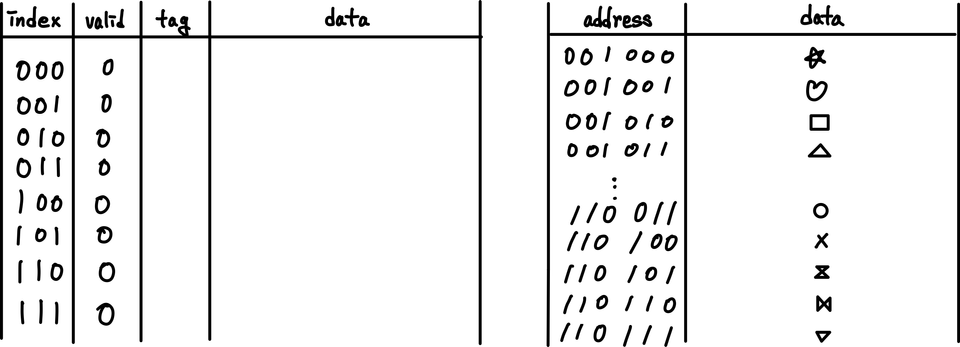
- 001011 요청
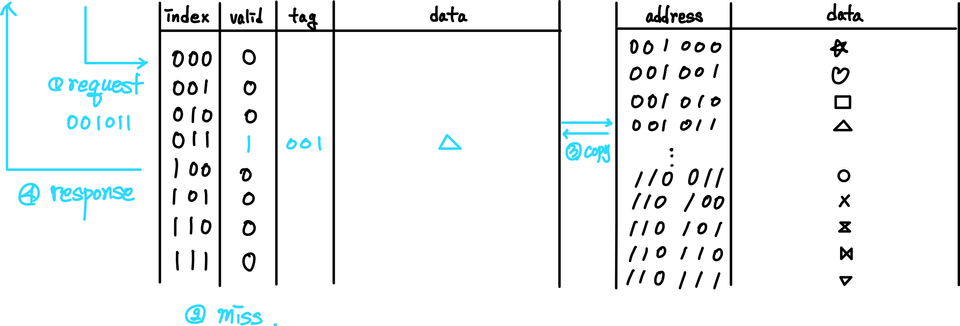
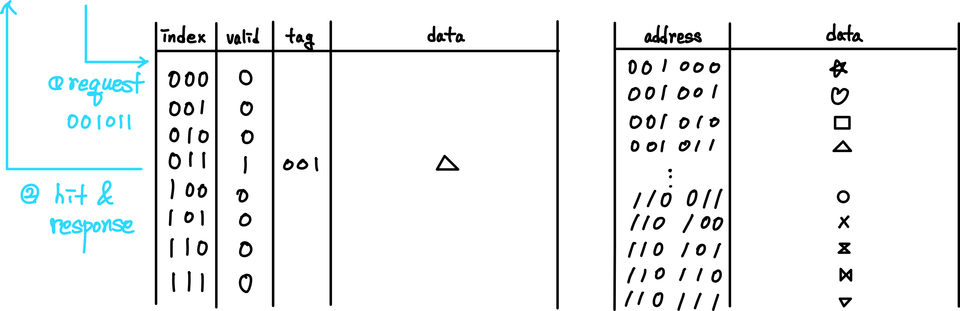
- 001011 재요청
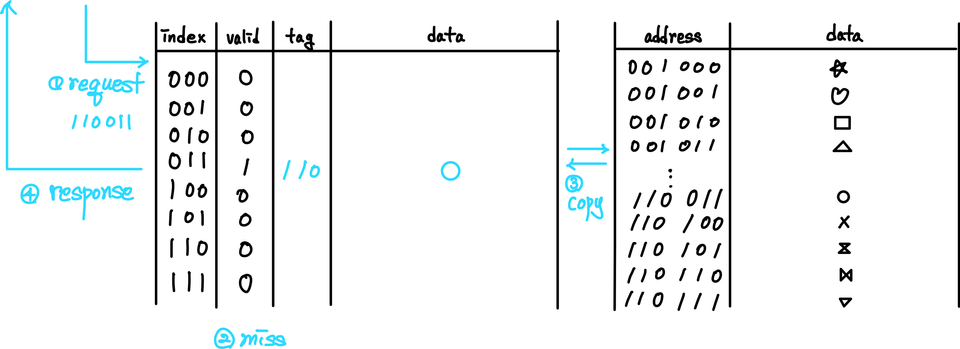
- 110011 요청
Block 단위를 4Bytes로 했다면, 하나의 word 단위가 Block의 단위가 될 것이다. 그렇지 않고 더 큰 단위로 Block을 저장할 수도 있다. 일반적으로는 이 Block의 단위를 늘리면 miss rate를 낮출 수 있다. 근처의 데이터를 한 번에 여러 개 가지므로, spatial locality를 활용할 수 있다. 하지만, 과도하게 늘리게 되면, 오히려 이로 인해서 index가 표현할 수 있는 범위가 점점 작아진다. (한 마디로 cache의 전체 크기(용량)은 고정이기 때문에, 가로를 의미하는 block의 사이즈가 늘어나면, 세로를 의미하는 index의 범위가 줄어들 수 밖에 없다.) 이로 인해서 block size를 너무 크게 늘리게 되어도, miss rate는 증가하게 된다. 뿐만 아니라 miss penalty도 크게 증가한다. 해당 데이터를 cache에 끌어오는 동안의 시간이 증가할 것이기 때문이다. 따라서, 적당한 크기의 block 사이즈를 지정해야 한다.
마지막으로, Cache를 읽기를 요청하였지만 해당 정보가 없는 경우 이를 Miss라고 하는데, Miss가 발생하면 이 데이터를 Main Memory에서 불러오기 위해서 어쩔 수 없이 우리는 stall을 수행해야 한다. 이러한 Miss는 굉장한 비용을 발생시키기 때문에 대게 세가지 방식에 의해서 이를 해결한다.
- Multiprocess or Multithread 환경에서는 다른 process를 해당 stall 동안 실행시켜서 이를 해결한다.
- OoO(Out of Order) Execution을 지원하는 장비에서는 이를 통해서 stall을 방지한다.
- Software를 개발할 당시에 해당 사항을 인지하고 최적화를 수행하는 것이다. cache의 hit 정도를 아래 그림에서 오른쪽과 같이 설정하게 되면, 결론적으로 hit 확률이 급격하게 증가하는 것을 알 수 있다. 이런식으로 Cache 크기에 유의하여 소프트웨어를 해당 장치에 최적화하는 방식도 존재한다.
Write
데이터를 Main Memory로 write하는 상황을 생각해보자. cache에서 작업을 진행하여 해당 위치에만 데이터를 최신화하게 되면, 필연적으로 cache와 Main Memory 사이에서 불일치가 발생할 수 밖에 없다. 따라서, 이를 해결하기 위한 방법이 세 가지가 있다.
- Write Through 가장 간단한 방법으로, write가 발생하면, 모든 저장 장치의 일관성을 유지하기 위해 모두 update 해주는 것이다. 그러나, 이 write의 비용이 엄청나게 크다는 것을 알기 때문에 이를 최대한 적게 하는 것이 사실상 performance 향상에 핵심이라고 생각하면, 이는 실제로 사용하기에는 무리가 있다.
- Write Buffer Main Memory에 쓰이기를 기다리는 buffer를 만들어 놓고, 해당 장치에서 write를 일임하여 놓는 방식이다. 이를 이용하게 되면, Write의 완료를 cache에서 더 이상 기달릴 필요가 없다. 하지만, Write 명령어를 processor가 처라하는 속도가 buffer가 Main Memory에 쓰는 속도보다 훨씬 빠르기 때문에 당연하게 buffer가 꽉찰 수 있다. 그렇게 되면, 반드시 공간이 날 때까지 stall을 해야만 한다.
- Write Back 이 방식은 일관성을 포기하는 방식이다. 즉, 데이터를 가지고 있다가 실제로 이 값이 다른 값으로 변경될 때, cache의 특정 index에 있는 값이 다른 tag의 값으로 변경될 때에만 데이터를 쓰는 방식이다. 또는 강제적으로 하위 memory로의 저장을 요구할 경우에만 쓰도록 한다. 이를 이용하면, 성능은 확연히 올라가지만, 불일치성으로 인해 발생하는 문제를 해결하기 위해서 더 복잡한 요구사항이 발생한다. (일단 cache의 table에 각 row에 해당 값이 하위 Memory에서 copy된 이후로 변경되었는지를 표시하는 dirty bit가 필요하며, multi processor 환경에서는 더 큰 문제를 야기한다.)
더 나은 Cache 저장법
Directed Mapping을 통해서 Cache에 데이터를 저장하게 되면, 특정 Block이 위치할 수 있는 장소가 고정되어 버린다. 만약, index가 겹치는 값이 동시에 여러 번 사용된다면, miss rate가 크게 증가할 수 밖에 없다. 여기서, cache의 위치를 고정하지 않고, 자유롭게 하여 이러한 문제는 크게 줄일려고 하는 방법이 있다.
tag에 모든 address 값을 저장하고, index를 address의 값으로 전혀 사용하지 않는 방식이 있다. 이것을 full-associative cache라고 한다. 이 경우에는 해당하는 index 범위에서 tag가 존재하는지를 확인하기 위해서 추가적인 연산이 필요하지만, hardware 장치를 추가적으로 배치하여 이를 동시에 실행시켜 성능을 향상시키는 방식을 택한다. 이 방식은 결론적으로 많은 hardware 장비를 추가적으로 요구하기 때문에 매우 비싸진다. 따라서, 적당한 합의점을 찾는 것이 set-associative cache이다. 이는 index 값을 일부만 이용하는 방식이라고 할 수 있다. 즉, 3bits를 index로 사용하는 cache에서 상위 n개의 bit만 실제로 사용하여 표현하는 것이다. 동일한 index를 가진 block은 존재하게 된다. 여기서, 이제부터 tag를 통해서 사용해서 검색을 수행하는 것이다. 따라서, 만약 n이 전체 bit 수와 같아 진다면, 이것이 full-associative cache가 되는 것이고, n = 0이라면, 일반적인 Directed Mapping이 되는 것이다.
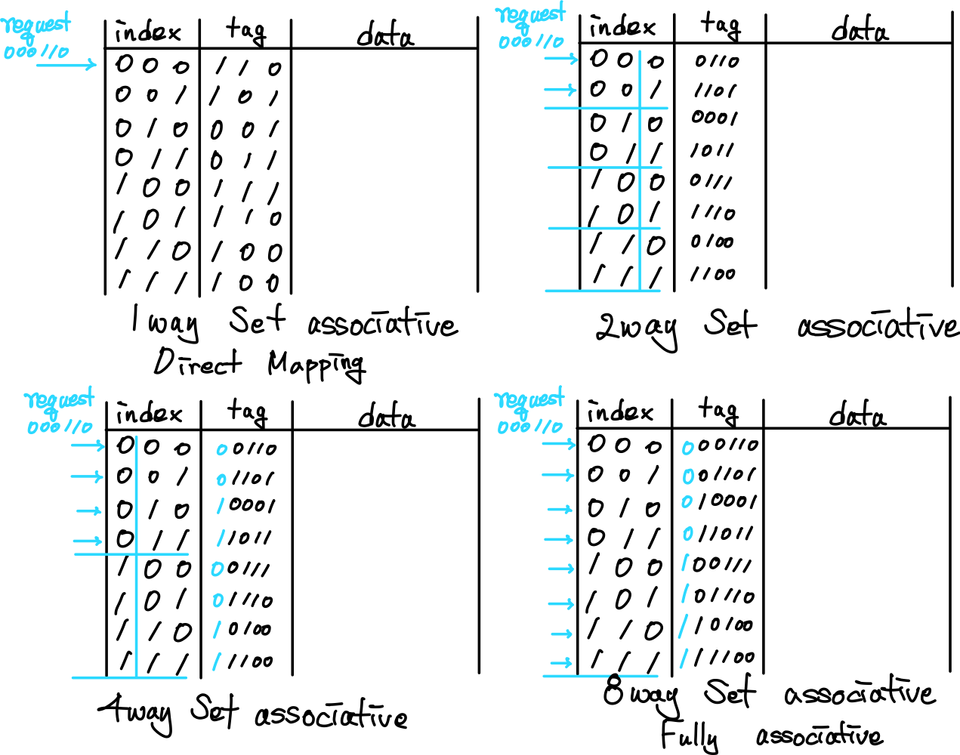
그렇다면, 이렇게 여러 개의 index가 data를 담을 수 있는 그릇이 될 때, 어느 위치에 값을 덮어 씌우는 것이 현명할 것인가는 temporal locality에 따라서 우리는 가장 쓰인지 오래된 index에 값을 덮어씌운다. 이것이 LRU(Least Recently Used) 방식이다. 이를 구현하기 위해서는 cache에 추가적인 reference bit라는 것을 위치시킨다.
MultiLevel Cache
이제 cache를 여러 개 층(multilevel cache)을 이루어 사용한다고 해보자. process에 가까운 쪽을 primary cache라고 하고, 그 다음을 secondary cache라고 하자. 만약, primary cache에서 miss가 발생했을 대, secondary cache에 있으면, miss penalty를 줄일 수 있을 것이다. 하지만, secondary cache도 miss가 나면, miss penalty자체가 증가한다. 왜냐하면, secondary 로 불러오고, 다시 primary로 옮겨야 하기 때문이다. 그렇기에 무조건 cache를 많이 둔다고 좋은 것은 아니다. 적절한 cahce를 설정하는 것이 중요하고, 대게 이는 3개 정도로 한다.
그리고 직관적으로 각 cache를 보면, primary cache는 hit time을 줄이는 것이 목표이고, secondary cache는 miss rate를 줄여야 한다. 그래서, primary cache에서는 block size를 줄이고, associative의 크기를 줄이지만, secondary cache에서는 block size를 키울 뿐만 아니라 associative의 크기 역시 키우는 것이 일반적이다.
Virtual Memory
Main Memory를 안정적으로 관리하기 위해서, Virtual Memory라는 개념을 도입한다. 이는 실제로 존재하는 Main Memory와 Secondary Storage의 주소(Physical Address)를 가상의 주소(Virtual Address)로 바꾸고, 필요에 따라 이를 번역하여 사용함으로써, 하나의 process가 마치 Main Memory 하나를 장악하고 있는 거 같은 느낌을 느끼도록 할 수 있다. 왜냐하면, 당장에 쓰지 않는 process의 data는 Secondary Storage로 빼놓고, Virtual Address로 번역 시에는 해당 위치를 가르키도록 하면 된다. 그러면, 마치 각 process는 Main Memory 이상의 data를 갖고 있는 것 같다고 느낄 수 있다. 이러한 Virtual Memory를 이용하면 다음과 같은 작업을 쉽게할 수 있다.
- 동일한 장치에서 program 간의 Memory 영역을 구분할 때, 일반적으로 Main Memory에 있는 데이터 역시 locality에 따라 계속해서 바뀌게 되는데, 특정 process 전체 크기를 실행 중일 동안 계속해서 제공한다면, 유연한 동작이 어렵다. 따라서, Virtual Memory는 이를 더 쉽게 하도록 돕는다.
- 동일한 장치 내에서 돌아가는 Virtual Machine간의 Main Memory 영역을 구분할 때, 각 Virtual Memory는 Physical Memory로 번역되었을 때, 서로 충돌하지 않는 것을 보장하기 때문에 서로 다른 process간에 간섭이 없음을 보장할 수 있다.
- Main Memory 보다 큰 크기의 Program을 돌리고자 할 때, Main Memory 이상의 process를 돌리기 위해서는 Secondary Storage에 직접적인 접근을 수행해야 하는데, 이를 수행하지 않고, 실제로 현재 사용하지 않는 Memory 공간의 데이터는 Secondary Storage로 옮기고 이를 가르키는 Virtual Address만 바꾸어주면 되기 때문에, 쉽게 Main Memory 보다 큰 크기의 Program을 동작시키는 것도 가능하다.
Virtual Memory 방식은 각 program, Virtual Machine마다 고유한 address space를 가지기 때문에 각자 독립되었다고 볼 수 있다. 그렇기에 각자가 서로의 동작으로 인한 영향을 받지 않는다. 즉, 다른 process에서 사용 중인 Memory에 접근할 수 없을 뿐만 아니라 이들에 의해서 발생하는 Memory의 변화가 자신이 진행 중인 process에 영향을 미치지 않는다. 즉, protection를 제공한다고 할 수 있다.
또한, program을 상호간의 영향이 없는 조각으로 나눈 Overlay 단위로 나누어 초과되는 용량은 Secondary Storage에 상주시키고, 필요에 따라 Main Memory로 올려서 실행시킬 수 있다. 따라서, 용량이 부족한 Main Memory에서도 이보다 큰 크기의 Program을 동작시킬 수 있다.
Cache의 방식과 매우 유사하지만, 언어의 기원이 다르기 때문에 여기서는 Block을 Page라고 부른다. 그리고, 이 Page의 크기는 Page Offset이라고 표기한다. 따라서, Virtual Address는 사실상 두 개의 Part로 나뉘어진다. 첫 번째는 Virtual Page Number이고, 하나의 Page offset이다. 또한, Miss는 Page Fault라는 말로 바뀌어진다. 마지막으로, Virtual Address에 Mapping 되는 Physical Address를 Physical Page Number와 Page offset으로 이루어진다.
위에서 말한 것처럼 Virtual Address를 Physical Address로 바꾸는 과정을 Address Translation이라고 한다.
Page 관리
Virtual Page Number를 통해서 실제 Physical Page Number로 변환하기
기존의 Cache에서도 Miss로 인한 비용도 컸지만, Page Fault의 비용은 이보다도 훨씬 크다고 할 수 있다. 이를 막기 위해서, Cache에서는 Full Associative한 구조를 가져갔지만, Main Memory는 Cache보다 훨씬 크기 때문에 이를 위한 추가적인 Hardware를 추가하는 것은 경제적으로 불가능하다고 볼 수 있다. 따라서, Main Memory에 존재하는 Page의 Address를 Mapping하기 위해서 table을 이용한다. 이를 Page Table이라고 부른다. 이는 Main Memory에 상중하고 있다. 각 각의 program은 고유의 Page Table을 하나씩 가지게 되며, Page Table 자체의 처음과 끝을 가르키는 register를 가지고 있다(Page Table Register). 그리고 Page Table에는 Virtual Page가 지금 어느 Physical Address에 존재하는지에 대한 정보와 이것이 Main Memory에 있는지를 표기하는 Valid Bit가 존재한다. 만약, Valid Bit가 0이라면, 이는 해당 Page가 지금 Main Memory가 아닌 Secondary Storage에 존재한다는 뜻이다.
따라서, Page를 찾는 과정은 다음과 같다.
- Page Table Register를 기반으로 하여 Main Memory에서 Page Table을 찾는다.
- Virtual Address의 Virtual Page Number를 이용해서 Page Table에서 Page를 조회한다.
- Valid Bit를 확인하여 해당 Page가 현재 Main Memory에 존재하는지 아니면 Secondary Storage에 존재하는지를 확인한다.
- 이제 실제 Physical Page Number를 얻어와서, 기존의 Page Offset을 합치면, 이것이 Physical Address가 된다.
1 2 🤔 Page Table의 크기가 너무 크면 어떻게 될까? 3 4 Page가 너무 많아지면, Page Table의 크기가 너무 커질 수 있다. 5 따라서, 이를 해결하기 위해서 계층 구조를 가지고 정리한다. 6 즉, Page Table의 Table이 생기는 형태라고 보면 되겠다. 7
Page Fault
위에서 말한대로 Page Fault가 발생한다면, 즉 Valid Bit가 0인 경우, 해당 Page를 Secondary Storage에서 찾고, 이를 Main Memory의 어느 위치에 놓을지를 결정해야 한다.
우리가 번역한 Physical Address는 Secondary Storage의 직접적인 주소를 의미하기도 하지만 대게는 이를 이용해서 실제 Secondary Storage의 주소를 찾을 수 있도록 하는 자료구조를 가르키도록 되어있다. 그래서, 우리의 Operating System은 Process가 생성될 때, Process의 모든 Page를 Secondary Storage에 저장할 공간을 생성한다. 이를 Swap Space라고 부르며, 해당 Virtual Page가 실제 disk의 어디에 저장될지를 기록한 자료구조이다.
만약, 이제 모든 Main Memory가 Page로 가득 차 있다면, OS는 어떤 Page를 대체할 것인지를 선택한다. 이때는 LRU(Least Recently Used) Algorithm을 사용한다. 지금까지 가장 사용하지 않은 Page를 삭제하는 것이다. 이를 구현할 때는 Reference bit를 설정하고, 주기적으로 0으로 변경하기를 반복하면서, 해당 Page를 사용할 때마다 1로 변경주는 것을 수행하는 것이다. 그리고, Page Fault가 발생할 시에 Reference Bit가 0인 대상이 있다면, 이를 우선으로 제거하는 방식이다.
Write
Write하는 것은 굉장히 많은 시간을 소요한다. 따라서, Virtual Memory System에서는 이를 최소화하는 것을 목표로 하기 때문에 이전에 소개한 Write Back이 default이다.
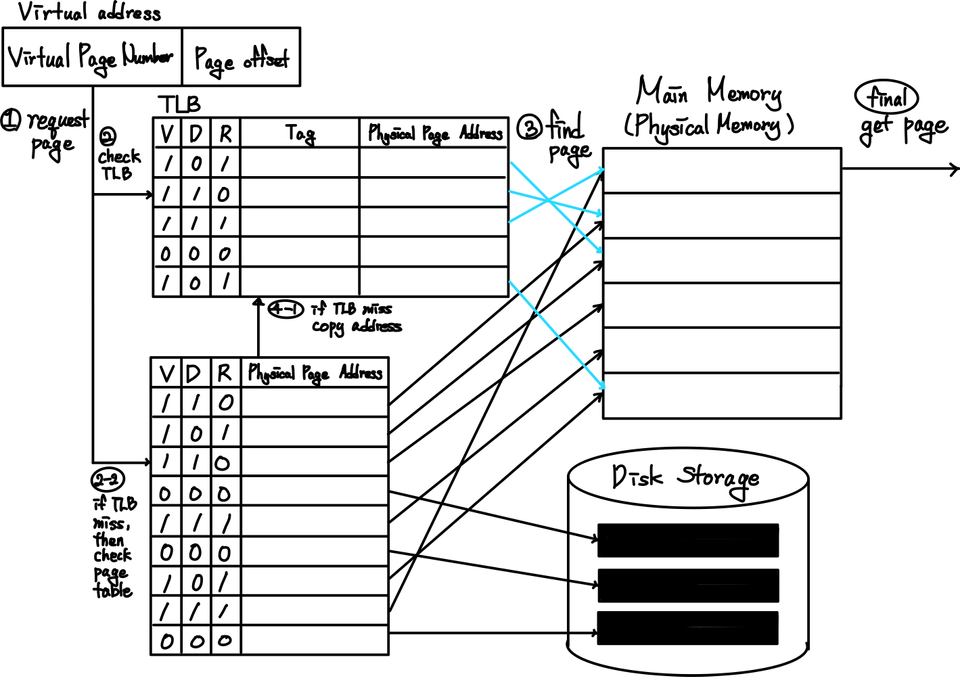
TLB를 이용한 변환작업 속도 향상
Page Table이 실제로 Main Memory에 저장되기 때문에 우리는 Page를 조회하기 위해서 결국 무조건 Main Memory에 한 번 접근해야 한다. 이는 많은 시간을 소요하는 동작이기에 이를 최소화할 방법이 필요했다. 또한, Temporarl / Spatial Locality에 따라 사용한 Page는 다시 사용할 확룰이 많다. 따라서, 대게의 processor에서는 이를 위한 특별한 cache를 추가로 가지고 있다. 이것이 TLB(Translate Lookaside Buffer)이다. (아마 Translation cache라고 부르는 것이 더 자연스럽긴 할 것이다.) 따라서, TLB는 Virtual Page Number와 Dirty Bit, 그리고 Reference Bit를 가진다. TLB를 설계할 때에는 fully associative하게 만드는 것이 기본이다. 왜냐하면, TLB 자체가 매우 작고, hit rate가 성능에 큰 영향을 미치기 때문이다. 이렇게 구축하는 것이 성능에 큰 도움이 된다. 또한, replacing을 할 때에도 LRU를 구현할 수도 있지만 대게 이를 구현하기가 너무 경제적으로 어렵기 때문에, 대부분의 system은 랜덤하게 고르는 것을 선택한다고 한다.
따라서, Page를 얻는 과정은 다음과 같다고 다시 요약할 수 있다.
- Page Table Register를 기반으로 하여 TLB에서 Page Table을 찾는다. 존재하지 않는다면, Main Memory에서 조회해야 한다.(TLB miss)
- Virtual Address의 Virtual Page Number를 이용해서 Page Table에서 Page를 조회한다.
- Valid Bit를 확인하여 해당 Page가 현재 Main Memory에 존재하는지 아니면 Secondary Storage에 존재하는지를 확인한다.
- 이제 실제 Physical Page Number를 얻어와서, 기존의 Page Offset을 합치면, 이것이 Physical Address가 된다.
- 이를 통해서, 조회를 수행하는데 만약, Secondary Storage에 있었다면, LRU를 이용해서 Page Swap을 수행하여 Page를 Main Memory로 올린다.
- 만약, TLB miss가 발생했었다면, 해당 Page 정보를 업데이트한다.
자주 헷갈릴 수 있는 TLB miss가 Page Fault가 아니라는 것을 꼭 명심하자.
Reference
- David A. Patterson, John L. Hennessy, Computer Organization and Design


Comments