해당 내용은 이전에 다루었던, 논리회로 리뷰 내용을 보고 보는 것을 추천합니다.
Intro
우리의 컴퓨터 시스템은 결국 Finite State Machine(유한상태장치)라고 할 수 있다. 즉, 순서에 따라 유한한 상태에서 다음 상태로 넘어가면서, Output을 계속해서 내보내는 장치라는 것이다. 이때 하나의 작업은 하나의 Clock 단위로 수행되며, 연속적은 작업 처리를 통해서 컴퓨터는 사용자가 요구한 명령을 수행하게 된다.
Processor
processor와 program의 성능을 측정하기 위해서 우리는 다음과 같은 식을 활용하였다.
2. post에서는 Instruction Count를 관리하고, 어떻게 계산되는지를 보았다면, 해당 포스팅에서는 Clock Cycle Time과 Clock Cycle per Instruction이 어떻게 구성되는지를 알아보며, 이들을 어떻게 줄일 수 있는지를 알아볼 것이다.
이를 위해서 우리는
- MIPS CPU의 가장 기본적인 구현
- pipeline된 MIPS
- Instruction 단계에서의 병렬화
를 살펴볼 것이다.
1 🤔 주의 2 3 해당 단계에서는 다음과 같은 사항은 배제한다. 4 1. multiply, shift, divide 연산 5 2. floating point 연산 6 7 결론적으로, 앞으로 구현할 MIPS에서는 다음과 같은 연산을 할 수 있다. 8 1. Memory에 접근하는 Load Word, Store Word 9 2. 기본 연산자 ADD, SUB, AND, OR, 등 10 3. Branch 구문 (BEQ, JUMP)
1. 기본적인 MIPS 구현(Single Cycle CPU)
기본적인 processor에서 program이 동작은 다음과 같다.
- PC(Program Counter)를 Memory에 보내서 code를 포함한 부분을 특정하여 Instruction을 불러온다.(Instruction Fetch)
- 하나 또는 두 개의 register를 읽어서 Instruction을 수행한다.
따라서, 이를 수행할 수 있는 논리 구조를 간략히 그려보면, 다음과 같은 형태를 가지게 됩니다.
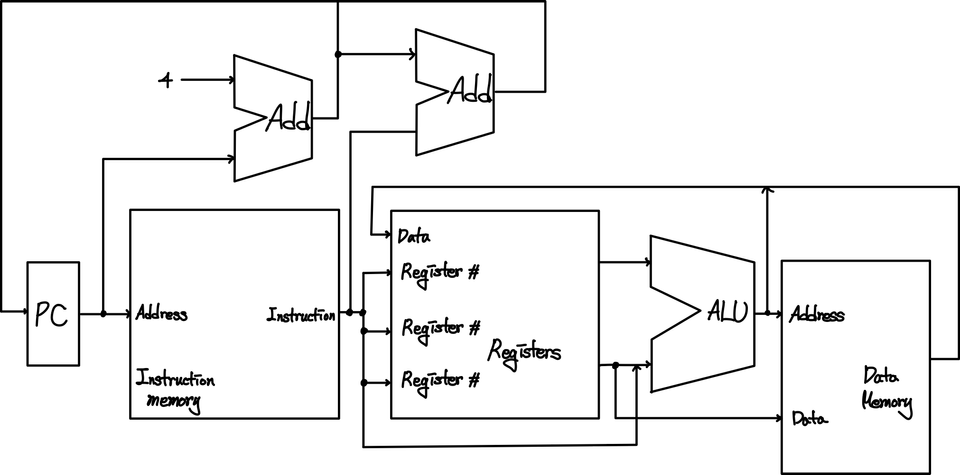
먼저, PC값의 형성 부분부터 보면 기본적으로 PC는 현재값에 4를 더하는 연산이기 때문에 상단에서 더한 값이 바로 다음 Clock에 적용된다고 할 수 있다. 그런데, 만약 Jump나 Branch 연산이 들어온다면, 해당 PC값에 특정값을 더한 결과로 이동하게 될 수 도 있다.
그리고, 나머지 부분은 PC를 통해서 첫번째 박스에서 Instruction을 골라내고, Instruction의 특정 부분에서 OP와 register 등에 대한 정보를 토대로 Register와 상수 등을 이용하여 ALU 장치에서 OP 정보에 따라 연산을 수행한 뒤에 결과값을 특정 Register에 돌려주거나 Memory에 저장하도록 한다.
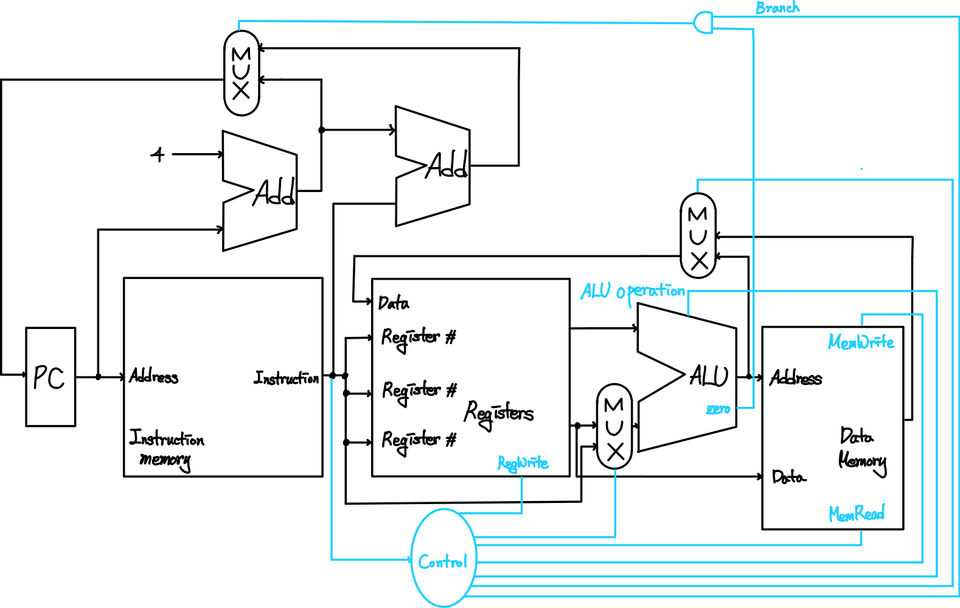
물론 위에서는 mux(Multiplexor)에서 사용하는 데이터에 대한 내용은 빠져있지만, 아래 그림을 보면 더 정확하게 이해할 수 있을 것이다. 여러가지 경우의 수 중 상황의 따라서 output이 다른 경우에 mux를 사용하게 되는데, 여기서는 Instruction의 특정부분을 통해서 Control bits를 얻어내고, mux를 설치하여 적절하게 행동하도록 제어하고 있다.
대표적인 예시로 아까 PC값을 선택하는 부분이 보다 명확하게 표시되는 것을 볼 수 있다. 현재 계산된 PC+4를 사용할 것인지 아니면, Branch 명령어에서 계산된 값을 사용할 것인지를 Control bit가 결정하는 것을 볼 수 있다.
이제부터는 각 단계별로 뜯어서 살펴본다.
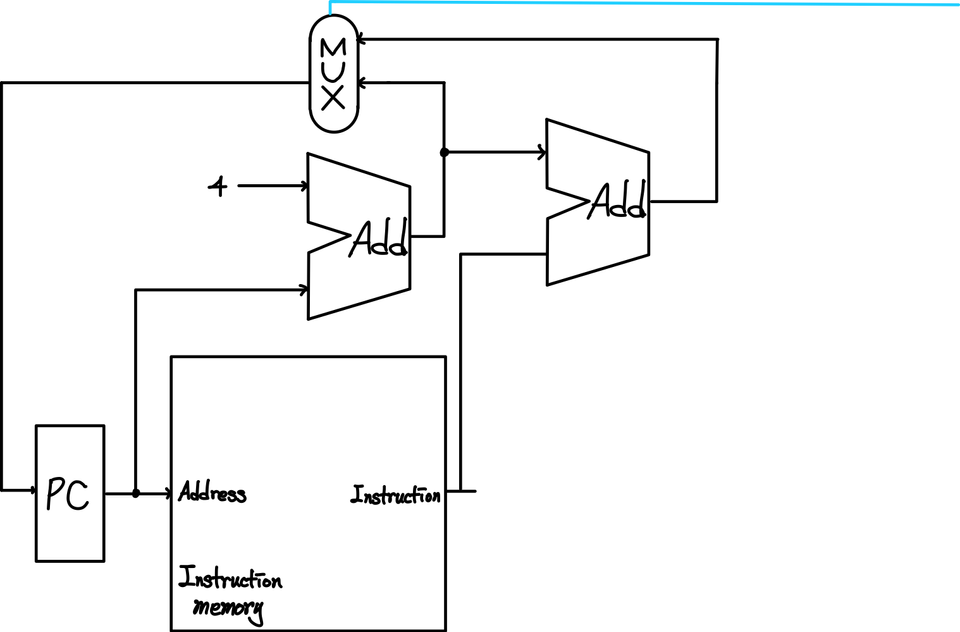
1) IF 단계 - Instruction Fetch
해당 단계에서는 PC에 저장된 값에 따라서, Memory에서 Instruction을 추출하면서 PC에 4가 더해지는 것을 볼 수 있다. 그리고, Instruction의 특정 부분과 연산이 수행되는 것을 볼 수 있는데 이는 Branch 구문에 의한 이동을 위해서 주소를 저장해놓는 것이다.
그리고, 이를 mux와 signal bit를 통해서, 최종적으로 다음 Program의 line을 가르킬 수 있다.
2) ID 단계 - Instruction Decode and Register File Read
해당 단계에서는 크게 두가지의 일을 한다.
첫 번째는, Instruction에 포함된 정보를 기반으로 하여 Register를 선택하고, 해당 Register에 해당하는 정보를 내보내는 것이며,
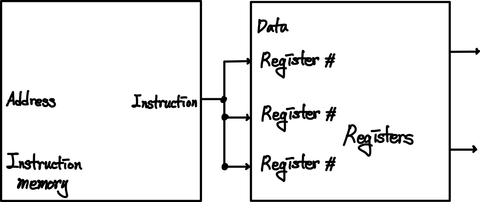
두 번째는, Control bits를 생성하는 역할이다.
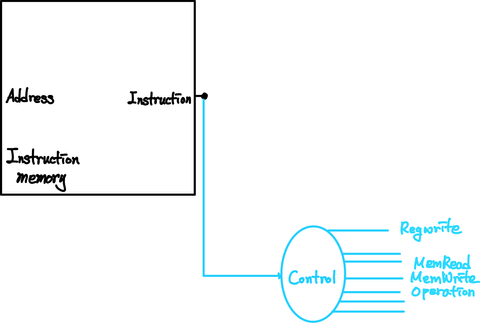
3) EX 단계 - Execution or Address Calculating
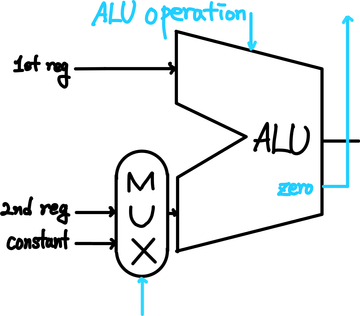
다음 단계에서는 R-Type, I-Type에 따라서 두번째(2nd) Register를 사용할지 아니면, 상수로 받아들일지를 선택해야 한다. 이는 이전 단계(ID)에서 생성했던 Control bit를 mux에 통과시키는 식으로 구현한다.
이후에는 control bit들을 통해서 연산의 종류를 선택한 후에, ALU 내부에서 연산을 수행하여 결과값을 내보낸다.
결과값은 일반적인 결과를 내보내며, 추가적으로 beq 또는 여타 연산의 결과를 쉽게 알리기 위해서 zero라는 output으로 결과값이 0인지를 알려준다. 이는 다른 beq와 같은 연산에서 control bit로 사용한다.
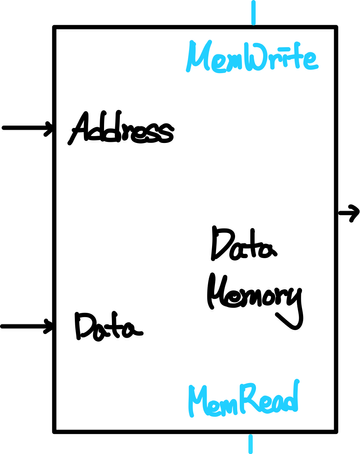
4) MEM 단계 - Data Memory Access
Data Memory에 접근하는 동작으로 만약 Memory에 데이터를 update하는 동작을 한다면, MemWrite가 1로 설정되어있고, 이를 보고 명령어를 처리하게 된다.(read도 동일하게 MemRead를 활용한다.) 물리적으로 CPU와 떨어져있는 장비이기 때문에 접근하는데 많은 시간이 소요된다. 따라서, MIPS의 Instruction 실행의 모든 단계들 중에서 가장 오랜 시간이 필요한 연산이라고 할 수 있다.
5) WB 단계 - Write Back
실제로 Register의 값을 update해주는 부분으로 register의 update는 Data Memory에서 값을 불러오거나 연산 결과를 받을 때 사용하기 때문에 둘 중에 어떤 경우인지를 확인하여 데이터를 update한다.
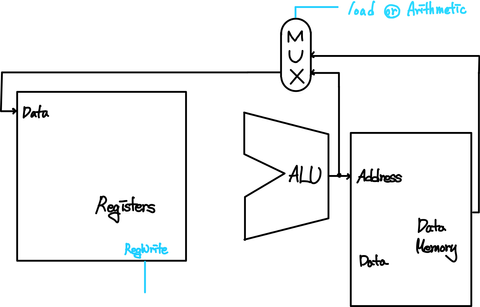
위와 같이 하나의 Instruction을 수행하기 위한 일련의 작업이 한 Clock을 단위로 실행되는 경우를 Single Cycle CPU라고 한다.
2. Pipelining
가장 기본적인 구조를 살펴보았으니 위의 형태를 최적화하기 위한 가장 효과적이였고, 모든 CPU에서 사용되고 있는 설계 방법을 설명할 것이다. 위의 과정을 보고 있으면 우리는 비효율을 하나 발견하게 된다. 바로 특정 단계가 실행 중인 동안에 해당 단계에 포함되지 않은 장비들은 놀려지고 있다는 점이다. 즉, 위에서 processor의 성능을 측정하는 지표인 Clock Cycle Time이 증가한다. 따라서, 모든 장비를 계속해서 실행시키기 위해서, 한 단계가 한 Clock이 되도록 하는 방법이 고안되었다.(Multi Cycle CPU)
하나의 예를 살펴보자.
세차장에 갔다고 하자. 우리는 당연히 일열로 서서 자신의 차례가 되기를 기다린다. 하나의 장비가 세차에 들어가기 전에 사람에 의해서 먼저 비누거품을 내는 단계가 있다면, 우리는 당연히 줄을 서있는 동안 세차장 아르바이트생이 비누칠을 해주기를 기다릴 것이다. 하지만, 해당 세차장에서는 만약 기다리는 동안 해주는 것이 아니라 세차 기계가 이전 차량에 대한 작업을 마치고 안정적으로 작업이 끝난 후에 비누칠을 해준다고 하자. 이것은 굉장한 짜증을 유발하는 요소가 될 것이다.
따라서, Single Cycle CPU를 사용하는 것은 하드웨어 장비를 최적화하지 못한 사례라고 할 수 있다.
위와 같이 단게를 나누어 여러 Cycle에 나누어 하나의 명령어를 처리하게 되면, 우리는 다음과 같은 효과를 얻게 된다.
- Clock Cycle Time이 줄어든다.
- 하나의 CPU가 동시에 여러 개의 명령어를 실행하게 할 수도 있다.(Instruction Overlapping)
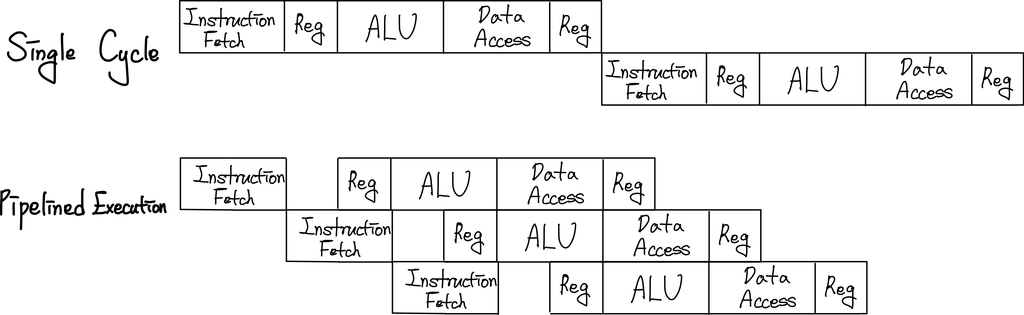
이렇게 Instruction을 동시에(병렬적으로) 실행할 수 있다면, 1개의 Cycle 동안 Hardware 장치의 잉여 시간을 최소화할 수 있다.
하지만, tradeoff 역시 존재한다.
- 각 단계의 연산이 끝난 후에 해당 값을 보관할 추가적인 하드웨어 장비(register)가 필요하다.
- Clock이 올라가고, 떨어지는 동안의 미세한 시간의 추가로 시간 비용이 증가한다.
- Clock Cycle Time은 반드시 하나의 상수로 정해져야 하기 때문에 가장 실행 시간이 긴 단계에 의존하게 된다. 즉, 실행시간이 더 짧은 단계라고 할지라도 다른 긴 단계가 있다면 기다려야 한다.
- 2와 3번을 이유로 결론상 하나의 Instruction을 수행하는데 걸리는 시간은 증가할 수 밖에 없다. 그렇기에 결론상 단계를 생각없이 무조건 잘게 자른다고 좋은 것이 아니다. 바로 균등하게 많이 나눌 수 있는 만큼 나누는 것이 좋은 것이다.
- Instruction을 동시에 실행하는 것으로 인한 문제가 발생할 수 있다(Hazard). 이는 바로 다음 부분에서 다룬다.
Hazard
Harzard는 아래와 같이 총 3가지의 종류가 있다.
1. Structural Hazard
Hardware가 구조적으로 동시에 특정 Instruction 조합을 처리하지 못할 경우를 의미한다. 즉, 서로 다른 pipeline stage에서 동일한 resource(Hardware)에 접근하고자 할 때 발생할 수 있다. 만약 Instruction Memory와 Data Memory의 분리가 되어 있지 않은 경우에는 이러한 문제가 IF, MEM 단계에서 발생할 수도 있지만, MIPS에서는 발생하지 않는다.
2. Data Hazard
바로 Instruction이 서로 연관(의존)되어있을 때의 문제이다.
다음과 같은 상황을 가정해보자. 우리가 memory에서 데이터를 불러와서 3을 더하는 연산을 한다고 하자. 그렇다면 명령어는 다음과 같다.
1lw $v 0 2addi $v 3
이를 실행하면 불행하게도 load가 채 끝나기도 전에 채워지지 않은 $v에 3이 더해지는 것을 알 수 있다.
이를 해결하기 위해서 3가지의 선택지가 있다.
- 의존성이 있는 명령어가 실행 중인 경우 끝날 때까지 대기 (Stall) 가장 간단한 방법이지만, pipelining을 통한 성능 향상을 감소시킬 수 있다.
- Compiler 단에서 의존이 발생하는 Instruction 사이에 순서가 상관없는 Instruction을 끼워넣어서 resource가 낭비되지 않으면서 hazard가 발생하지 않도록 한다. (Reordering) Hazard를 해결하는 좋은 방법이지만, 항상 이것이 가능할 수는 없다.
- 추가적인 Hardware를 사용하여 결과값을 필요로 하는 resource에게는 단계를 생략하고 넘긴다. (Forwarding, Bypassing) 현재까지는 가장 괜찮다고 받아들여지는 방법이다. 예를 들어서, EX 단계에서 ALU 연산이 끝나자마자 Write Back을 자체적으로 수행해주면 총 3번의 stall을 1번으로 줄일 수 있다.
3. Control Hazard
Branch Hazard라고도 불리며, 이전 Instruction의 결과에 따라서 실행시킬 Instruction이 변화할 때, 어느 Instruction을 실행시킬지 알 수 없기 때문에 발생하는 Hazard이다. (JUMP, BEQ)
이 경우에도 총 3가지의 선택지를 가진다.
- 성공적으로 분기문이 실행될 때까지 대기한다.(Stall)
- 어느 곳으로 Branch가 될지를 예상하여, 미리 시행해둔다. (Branch Prediction)
Resource를 최적화한다. 별도의 hardware를 설치하여 미리 JUMP 및 Branch address를 계산해 놓는다(Hardware Optimization)는 가정이 필요하다. 또한, 예측이 얼마나 적중하는가 역시 굉장히 중요한 요소로 작용한다.
대게 이러한 예측은 두 가지의 종류가 있다.
- 정적 예측 쉽게 생각할 수 있는 것은 반드시 실패한다고 생각하거나 성공한다고 생각해서 진행하는 방식이다. 좀 더 복잡한 방식은 loop문에 의한 branch인 경우 branch가 수행될 확률이 높다는 것을 기반으로 하여 성공 가능성이 크다고 예측할 수 있다.
- 동적 예측 이전 예측들을 기반으로 하여 현재 예측을 수행하는 방식이다. 이를 사용하면, 여러 번 반복되는 행위에 대한 예측율이 상당히 높아진다. 대게, 우리가 하는 분기문이 loop 등에 의한 경우가 많으므로 좋다고 할 수 있다. 또한, 최근에는 machine learning을 활용하여 예측을 수행하는 방식 또한 나오고 있다.
- Branch 여부에 상관없는 요청을 Control Hazard에 의해서 발생하는 구간에 넣는다. (Delayed Decision)
Parallelism via Instruction
Pipelining을 통해서, Instruction을 동시에 여러 개 실행시킬 수 있는 환경이 구축되었다. 그 와중에 resourece 자체를 하나 이상 두어서 Instruction을 동시에 수행할 수 있도록 하는 방식이 고안되었는데, 이를 Multiple Issue processor라고 한다.
이를 대표하는 방식은 크게 두가지로 나눌 수 있다.
1. Static Multiple Issue
이는 compiler가 program을 기계어로 번역하는 과정에서 이루어지며, 대표적으로 다음과 같은 것들이 있다.
- VLIW(Very Long Instruction Word) 의존성이 없는 여러 Instruction을 하나의 Instruction으로 뭉쳐서 실행시키는 방법이다. 이를 통해서 중첩되는 OPCODE 및 기타 처리 등을 최소화할 수 있다. Processor가 해당 기능을 지원하는 경우에만 사용가능하다.
- Loop Unrolling loop를 풀어서 여러 개의 Instruction으로 만들어서 branch로 인한 비용을 줄일 수 있다.
2. Dynamic Multiple Issue
processor에서 직접 Instruction이 실행되는 동안 이루어진다. 이는 여러 개의 pipeline을 CPU에 두어 이를 SuperScalar 방식이라고도 한다. 이를 효율적으로 수행하기 위해서는 앞 서 보았던 Compiler 단에서의 조율도 필요하며, 실행 중에 Instruction을 어떻게 나눌 것인가에 대한 Dynamic Scheduling 역시 매우 중요하다. 대표적인 예시가 OoO(Out of Order) Execution을 이용하는 것이다. Instruction의 Fetch를 순서대로가 아닌 의존성에 알맞게 실행되도록 조절하는 방식이다.
Reference
- David A. Patterson, John L. Hennessy, Computer Organization and Design


Comments