Intro
우리가 원하는 것은 강한 performance를 발휘하면서도, 가용성(availability, 끊김 없이 사용할 수 있는 능력의 정도)가 높은 computer를 만드는 것이다. 이를 위해서, 우리는 단순히 하나의 processor를 정교하게 만들기보다는 동등한 기능을 하는 여러 개의 processor를 연결하여 사용하는 것이 더 효율적이라는 것이라는 것을 알아냈다. (이를 software가 잘 활용할 수만 있다면, 성능이 크게 향상될 것이다.)
- 하나의 장치를 동작시키는 방식보다 적은 에너지로 같은 작업을 수행할 수 있다. (동시에 실행시키기 때문에 더 짧은 시간 사용할 수 있다.)
- n개의 processor에서 하나가 실패하여도 n-1개는 정상 작동하기 때문에 전체 시스템은 문제 없이 동작한다. (Redundant, 추가자원을 통해서 가용성을 향상시킴)
이에 따라 우리는 multi-processor를 사용한다. 이는 multi-processor가 어떻게 존재하느냐에 따라서 다음과 같은 형태로 나눈다.
- Multicore Microprocessor : 하나의 IC(집적 회로) 칩에 여러 개의 processor(core)가 존재한다.
- Multiple Processor : IC칩의 갯수를 늘린다.
- Cluster System : Machine(Computer) 자체의 갯수를 늘린다.
따라서, 개인 PC에서는 Multiple Multicore Microprocessor를 지원하고, 있는 상황이고, Datacenter와 같은 환경에서는 이러한 Machine들이 여러 개 존재하는 Cluster System이라고 생각하면 되겠다.
또한, 이용하는 방식에 따라 크게 두 가지로 나눌 수 있다.
- Task Level Parallelism(=Process Level Parallelism) : 동시에 독립된 여러 program을 실행시키는 방식
- Parallel Processing Program : 동시에 여러 개의 processor를 이용하여 하나의 program을 실행시키는 방식
Parallel Processing Program의 구현
하나의 작업을 더 빠르게 처리하기 위하여 multiple processor를 사용하는 software를 작성하는 것은 어렵다. 이는 processor의 수가 늘어날 수록 심해진다. multiprocessor program을 이용할 경우에, 수가 늘어날 수록 우리는 다음과 같은 작업에 대한 부담을 가질 수 밖에 없다.
- Scheduling : process 또는 thread를 scheduling하여 어떤 것을 먼저 실행시킬지에 대한 scheduling 역시 큰 부담이다.
- Partitioning : Memory의 구간을 각 processor에게 어떻게 나누고 서로 독립되게 존재하기 위한 관리를 수행하는 것 역시 큰 부담이 된다.
- Balancing the Load : 작업을 각 processor에게 균등히 분배하는 것 역시 어렵다.
- Time to Synchronize : 여러 개가 동시에 하나의 process를 실행시키면, 읽고 쓰기에서 충돌이 발생하는 것에 의한 문제가 발생하고 이를 해결하기 위해서 시간을 사용할 수 밖에 없다.
- Overhead for Communication : 각 processor간의 의사소통에 너무 큰 비용이 발생하는 경우 오히려 하나의 processor가 실행시키는 것보다 더 많은 시간을 요구할 수도 있다.
이 모든 것을 software에서 제대로 관리할 수 있을 때, 그제서야 우리는 multi processor 시스템을 제대로 활용할 수 있는 것이다.
우리가 processor의 갯수를 늘림으로써 얻을 수 있는 혜택은 각 processor에 전달되는 작업의 수를 균등하게 나누어, 기존에 하나의 processor가 할 수 없던 일을 처리(weak scaling)하거나, 기존의 문제를 더 빠르게 처리(strong scaling)할 수 있다.
Data Stream, Instruction Stream
processor들로 들어오는 data의 양을 의미하는 Data Stream과 instruction의 양을 의미하는 Instruction Stream에 따라서, 우리는 각 processor들을 다양한 이름으로 부른다.
- SISD(Single Instruction Stream, Single Data Stream) : 대게 single processor일 경우 이와 같은 형태를 채택한다.
- MIMD(Multiple Instrunction Stream, Multiple Data Stream) : Multiple Processor System에서는 당연히 이와 같은 시스템을 채택한다.
- MISD(Multiple Instrunction Stream, Single Data Stream) : 잘 사용하지 않는 형태이다. 대게는 Data의 처리가 더 많이 발생하기 때문이다.
- SIMD(Single Instruction Stream, Multiple Data Stream) : 하나의 Instruction을 이용하여 복합적인 여러 개의 데이터를 한 번에 처리하는 vector 연산 등을 빠르게 처리할 수 있다.
- vector 연산 하나가 for loop 하나를 의미할 수 있다. 이는 processor part의 각 pipeline 단계에서 fetch와 decode에 의한 비용을 크게 감소시킬 수 있다.
- 하나의 vector 연산은 내부에서 각각이 독립적으로 수행되기 때문에, data hazard를 check하는 비용이 발생하지 않는다. 👉 따라서, vector의 각 요소를 모두 검사하는 것이 아닌 vector 외부 간의 data hazard 유무만 확인하면 된다.
- Main Memory에서 데이터를 불러올 경우에도 각 요소를 불러오는 것이 아닌 한 번에 가져올 수 있기 때문에 매우 빠르다.
- Loop를 표현이 vector 연산으로 대체되기 때문에, Loop Branch가 줄어든다.
Hardware Multithreading
programmer의 입장에서 MIMD는 hardware multithreading처럼 동작한다고 생각하게 한다. 이는 processor의 사용성을 최대화하기 위해서, 특정 thread가 stall 되었을 때, 다른 thread를 수행하도록 하는 방식이다. 즉, 하나의 processor에서 여러 개의 thread를 실행시킨다는 것이다. 그러기 위해 사실상 여러 processor가 존재하는 multiprocessor 환경에서 서로간 실행 환경을 서로 공유해야 한다. 이를 실현하려면, 각 thread의 독립된 상태를 복사할 수 있어야 한다. 즉, 각 각의 register file과 PC가 존재해야 한다. 이들 간의 Memory 공유 같은 경우는 이전에 보았던 Virtual Memory 정보를 공유하여 수행하게 된다. 그리고 무엇보다 중요한 것은 이 실행하는 thread를 바꾸는 시간적 비용이 작아야 한다. 이를 위해서, process가 아닌 thread를 바꾸는 것이다. process를 바꾸는 것보다는 비용이 훨씬 적기 때문이다.
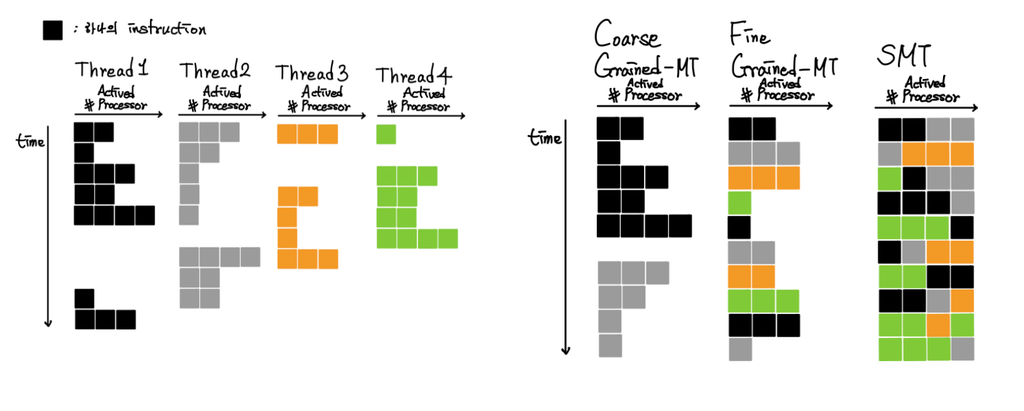
thread를 변경 시에 어떤 방법을 택할 것인가 역시 중요한데, 아래와 같은 방법론이 존재한다.
1. Fine Grained Multithreading
thread의 명령어를 round robine 방식을 이용하여 매번 바꾸면서 실행시키는 방식이다. 변경한 thread 역시 stall이 된 thread라면, 건너뛰고 다음 thread를 실행시킨다.
- 장점 : stall 기간이 짧던 길던 이로 인한 손실을 감추고, 그 동안 다른 thread를 실행시킬 수 있다.
- 단점 : 실행 준비가 된 상태(stall이 아닌 상태)에서도 다음 차례가 올 때까지 반드시 기다려야 하기 때문에 하나의 thread에 대한 처리 속도가 dramatic하게 줄어든다.
2. Coarse Grained Multithreading
하나의 thread에 대한 Instruction만 처리하다가 stall이 발생했을 때에만 thread를 변경하도록 하는 방식이다.
- 장점 : 하나의 thread에 대한 처리 속도의 손실이 적고, switching을 빨리 하는 것에 대한 부담이 적다.
- 단점 : 하나의 thread에 대한 Instruction만 처리하기 때문에, thread를 변경하는 것에 대한 비용이 크다. (long pipeline setup time) 따라서, 짧은 기간의 stall인 경우에는 해당 stall이 끝나길 기다린다.
3. Simultaneous Multithreading(SMT)
Thread Level에서 Parallelism과 Instruction Level에서의 Parallelism을 동시에 수행하는 방식이다. Multiple Instruction 시스템에서는 더 많은 functional unit(register, pc, etc)이 있기 때문에 이를 Multi Threading에서도 적절히 사용할 수 있다는 접근법에서 나왔다. 여기서는 register renaming과 dynamic scheduling을 이용하여 multiple thread에서 여러 개의 Instruction을 빈틈없이 배치할 수 있다. 의존성은 dynamic scheduling이 해결하고, register renaming을 통해 필요에 따라 여분의 register를 불러와서 사용하는 것이 가능해졌다. 이를 통해서 위의 두 방식으로 할 수 없었던, multi processor를 최대한으로 사용하는 효과를 볼 수 있다.
GPU(Graphic Processing Unit)
game 산업 및 그래픽 분야의 큰 성장에 힘업어 graphic 처리에 대한 processor의 성능 향상이 필요했다. 즉, 기존 micro processor와 겉아 다용도로 사용되는 것이 아닌 graphic 연산만을 빠르게 처리할 수 있는 processor를 분리할 필요가 생긴 것이다. 이것만을 위해서 만들어진 것이 GPU이다.
GPU는 앞 서 설명한 Multi Threading 기술을 적극 도입했기 때문에 Memory 접근에 따른 Latency가 성능에 큰 영향을 미치지 않는다. 그런 만큼 반대로 높은 Bandwidth를 가진 저장 장치를 필요로 한다.
후에는 이 장치가 수행하는 vector 연산이 여러 용도로 사용됨에 따라 이를 위한 programming language들도 만들어졌다. 대표적인 것이 NVidia가 C를 통해서 만든 CUDA이다.
Reference
- David A. Patterson, John L. Hennessy, Computer Organization and Design


Comments