Clustering과 같은 Unsupervised Learning으로 Feature Selection 또는 Feature Extraction 등 여러가지 이름으로 불리는 Dimensionality Reduction 기법에 대해서 다룰 것이다. 특정 data에서 유의미한 정보를 얻기 위해서 우리는 data 전체를 볼 필요가 없다. 따라서, feature들을 최소한으로 줄이면서 유의미한 정보를 얻을 수만 있다면 굉장히 효율적인 inferencing과 learning을 할 수 있다.
Dimensionality Reduction
가장 AI가 활발하게 연구되고 있는 분야는 Vison과 Natural Language 분야일 것이다. 그리고 이들 분야의 공통점은 data의 크기가 굉장히 크다는 것이다. 예를 들어, 숫자를 표현하는 하나의 이미지가 1920×1080 정도의 화질이고, 검은 색 또는 흰색으로 구분하는 bitmap 형식이라고 하자. 이 때 우리가 각 image에 존재하는 숫자를 classification하고 싶은 경우, data에 사용되는 feature가 1920×1080=2,073,600이다. 상당히 큰 숫자이고, 화질이 커질 수록 그리고 색이 생길 수록 이 값은 커질 것이다. Natural Language 분야에서도 마찬가지이다. 영어 단어의 종류만 따져도 170,000개가 넘는다. 즉, 이들 각 각을 단순 one-hot encoding으로 표현한다면, data에 사용되는 feature의 수는 170,000개가 넘는다. 이렇게 feature의 수가 많아지면, 우리는 data를 효율적으로 학습시키기가 매우 어려워진다. 이를 해결하기 위해서는 feature의 수를 줄이는 것이 반드시 필요하다.
이를 위해서, 우리는 하나의 insight가 필요하다. data에서 필요한 부분이 눈으로 보이는 것이 아닐 수도 있다는 점이다. 예를 들어 우리가 10×10 크기의 bitmap에 숫자가 쓰여있다고 하자.
이때 우리가 갖는 경우의 수는 2100개일 것이다. 여기서 숫자 형태로 존재하지 않는 data가 사실은 더 많음에도 불구하고 우리는 이 경우의 수도 고려하는 dimension에서 inferencing과 learning을 수행하는 것이다. 이는 매우 비효율적이라고 할 수 있다. 따라서, 우리는 실제로 관측한 observed dimensionality보다는 더 훌륭한 true dimensionality를 찾아내는 것이 필요하다. 이를 위해서, 다양한 Dimensionality Reduction 관련 방법들이 존재한다. 그 중에서 PCA가 가장 일반적으로 많이 사용되고 있는 방법이다.
Principal Component Analysis
Principal Component Analysis(PCA)는 핵심이 되는 principal component(basis, 기저, 차원 축)를 재정의하여 차원을 줄이는 방법이다. 그렇다면, 어떤 basis가 좋은 basis인지를 알 수 있을까? 아마도 좋은 basis는 이전 basis에서 가지고 있던 정보들을 최대한 보존할 수 있다면 좋다고 할 수 있을 것이다. 그렇다면, 여기서 어떻게 information을 많이 보관할 수 있을지에 대한 통찰이 필요하다.
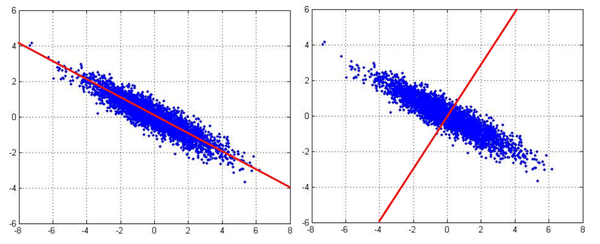
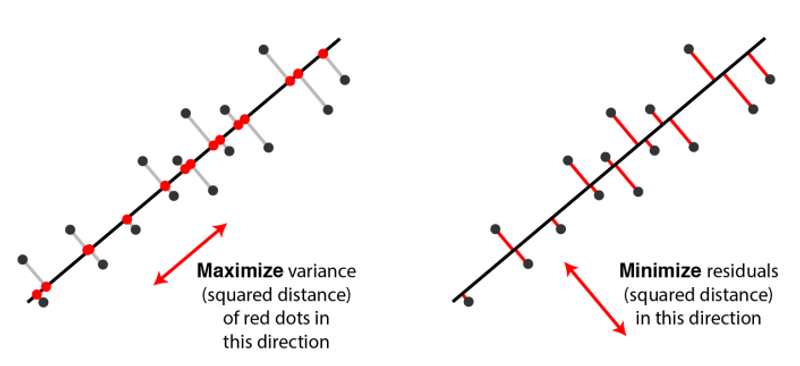
위의 그림을 봤을 때, 왼쪽과 오른쪽 중 어떤 basis가 더 좋은 basis일지를 보자. 차원을 옮긴다는 것은 기존 basis에서의 data를 새로운 basis로 projection하는 것이다. 다시 말해, 해당 축에 직각으로 data를 내려보내는 것이다. 그렇게 했을 때, 왼쪽 그림이 오른쪽 그림보다 더 넓게 data가 퍼지는 것을 알 수 있다. 즉, 차원 이동 시에 충돌로 인해 사라지는 data의 수가 더 적다는 것을 의미한다. 이에 따라 더 많은 정보를 포함하는 것은 data를 최대한 넓게 퍼트릴 수 있는 basis를 가지는 것이라고 할 수 있다. 따라서, PCA는 기존 basis보다 적은 수의 새로운 basis로 옮기는 과정에서 기존 dimension에서의 정보를 최대한 포함하기 위해서 variance가 최대가 되는 basis를 찾는 것이 목표이다. 그럼 이를 수학적으로 표현해볼 것이다. 우선은 이해를 위해서 새로운 basis의 수를 1이라고 가정하고 우리는 sample mean과 variance를 이용해서 이를 추론할 것이다. (해당 basis가 u1이다.)
결국 우리가 얻고자 하는 다른 basis에서의 variance를 구하기 위해서 우리는 기존 차원에서의 모든 data들의 covariance(Sij=Cov[xi,xj])를 구해야한다.
자 이제 이를 maximization하는 답을 찾아볼 것이다. 그러기 위해서, 우선 basis의 크기 역시 variance의 영향을 미치기 때문에 이를 unit vector로 제한해야 한다. 이를 종합하면 결론적으로 dimension을 1로 바꾸는 PCA는 다음과 같은 형태로 표현할 수 있다.
maximize subject to u1⊤Su1u1⊤u1=1
위의 maximization problem을 해결해보자. 그러면 다음과 같은 lagrange function을 얻을 수 있다.
L=u1⊤Su1+λ(1−u1⊤u1)
이를 미분하면 다음과 같다.
∂u1∂LSu1=2Su1−2λu1=0=λu1
즉, 우리가 찾고자 하는 basis는 S matrix의 eigenvector 중 하나의 eigenvector인 것이다. 간단하게 eigenvector와 eigenvalue가 뭔지를 설명하자면, 위처럼 동일한 vector에 대해서, matrix와 vector의 곱이 scalar와 vector과 동일하게 하는 scalar(eigenvalue)와 vector(eigenvector)를 의미한다. (후에 시간이 되면 해당 개념을 다루겠지만, 여기서는 eigenvalue와 eigenvector에 대한 개념은 생략한다.)
그리고 우리가 구한 식을 maximization 식에 한 번 대입하면 다음과 같은 결과를 얻을 수 있다.
따라서, eigenvalue 중 가장 큰 값을 가질 때의 eigenvector가 우리가 구하고자 하는 basis가 된다는 것을 알 수 있다. 또한, 결론적으로 u1⊤Su1=λ이기 때문에 λ가 variance가 된다는 것도 포인트 중 하나이다.
또한 최종적으로 이를 확장해서 이제 M개의 basis를 사용하는 PCA를 다음과 같이 표현할 수 있다.
maximize subject to i∈[M]∑ui⊤Suiui⊤uj=δij∀i,j∈[M](δij={10i=ji=j)
따라서, PCA는 data의 covariance matrix에 대한 eigenvalue decomposition을 통해 얻은 eigenvalue 중에 큰 값을 가지는 것을 총 M개 뽑고, 이에 상응하는 eigenvector들을 찾는 것이다. 그리고, 이에 따라서 우리가 가지는 M개의 basis의 eigenvalue(λ)의 합은 우리가 옮긴 차원에서 갖고 있는 총 variance를 의미한다.
Other Approaches
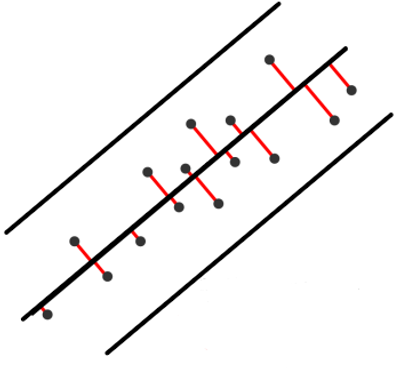
위에서 우리는 PCA를 variance를 최대로 하는 basis를 찾는 것으로 정의했다. 하지만, 관점을 바꿔서 문제를 projection error, 기존 data와 projected data 사이의 거리를 최소화할 수 있는 basis를 찾는 것으로 정의할 수도 있다. 이 또한 생각하기에 합리적이라고 생각할 수 있는데 이를 실제로 수학적으로 나타내면 어떻게 되는지 알아보겠다.
먼저, 우리가 총 D개의 unit vector가 있고, 이 중에 임의의 M개의 vector를 basis로 하는 차원으로 reduction을 한다고 해보자. 그렇다면, 우리는 다음과 같이 N개의 data들 중 하나인 xn를 표현할 수 있을 것이다.
여기서 의문이 들 수 있다. ∑i=M+1D 부분이 와닿지 않을 것이다. 왜냐하면, 우리는 projected data가 실제로는 ∑i=1M 부분만을 가지기 때문이다. 뒷 부분이 추가된 이유는 해당 M차원 data를 D차원의 공간에 표현할 때, 어느 부분을 중점으로 할지를 정한 것이다. 따라서, 앞 서 보았던 전체 data의 평균만큼을 남은 모든 방향에 더해준 것이다. 이 값은 모든 projected data에 동일하게 더해지는 상수값이라고 봐도 무방하다. 이래도 이해가 조금 어렵다면 아래 그림을 통해 이해할 수 있다.
위와 같이 3개의 vector는 1차원에서는 동일한 vector이다. 하지만, projected data와 원래 data간의 적절한 거리를 구하기 위해서는 중앙에 있는 형태로 basis로 옮겨야 한다. 이를 위해서 필요한 것이 뒤의 요소이다. 따라서, 우리는 아래식과 같이 두 projected data와 원래 data간의 거리를 구할 수 있다.
minimize subject to i=M+1∑Dui⊤Suiui⊤uj=δij∀i,j∈[M](δij={10i=ji=j)
기존 식과 다른 점이라면, maximization이 minimization으로 바뀌었고, 범위가 [1,M]에서 [M+1,D]로 바뀌었다는 점이다. 그리고, 우리는 다음과 같은 통찰을 얻을 수 있다. eigenvalue들 중에서 가장 큰 값부터 M번째로 큰 값을 구하는 것과 M+1부터 시작해서 가장 작은 eigenvalue를 찾는 과정은 동일하므로 두 식은 사실상 동일하다.
Very High Dimensional Data
일반적으로 우리가 PCA를 구하기 위해서 eigenvector를 구하는 비용은 O(D3)이다. 하지만, 차원이 data의 수보다 큰 경우에 약간의 꼼수를 쓸 수 있다. 간단하게 S를 (M x M) matrix에서 (N x N) matrix로 변환하여 사용하는 것이다. 이를 이용하면, O(N3)로 시간 복잡도를 바꾸는 것이 가능하다. 식은 아래를 참고 하자. 아래에서 사용하는 X는 각 행이 (xn−xˉ)⊤인 matrix이다.
PCA를 통해서 data를 다른 차원으로 옮기는 과정을 수행했다. 사실 이것으로 끝나기는 조금 아쉽다. 왜냐하면, 우리는 현재 가지고 있는 data에 대응하는 차원으로의 이동을 수행한 것이다. 즉, 우리가 실제로 inferencing 단계에서 unseen data를 보게 되었을 때 제대로 동작할지는 미지수라고 할 수 있다. 이를 극복하기 위해서, continueous한 형태를 만들어야 한다. 이를 위해서, PCA를 확률적으로 해석하는 것이 필요하다. 하지만, 여기서는 자세히 다루지 않는다. 후에 더 자세히 다루도록 하겠다.
Kernel PCA
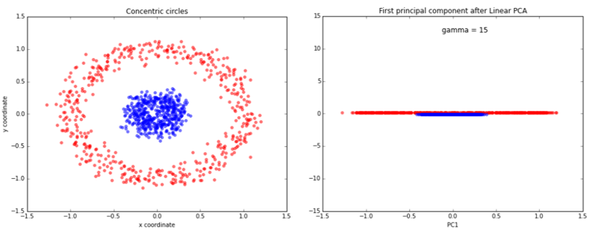
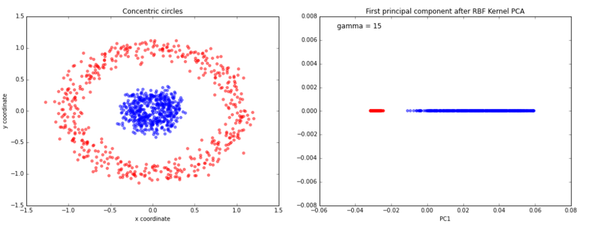
여태까지 앞에서 살펴봤던 PCA는 새로운 basis가 기존 Dimenalality에서 linear하게 만들었다. 하지만, 우리가 다루는 data가 사실은 그렇지 않은 형태일 가능성이 높다. 우리가 관측한 특징들에 의한 좌표 공간에서 선형 형태로 data가 존재하는게 아니라 더 복잡한 곡선 형태를 가질 수 있다. 가장 일반적인 data가 원형으로 이루어진 data 분포이다. 원형으로 반지름이 0.5이하인 data와 반지름이 1인 data를 구분하고 싶다고 하자. 일반적인 x, y 공간에서 linear basis를 이용해서 이를 적절하게 나누려면, dimensionality reduction에서는 정보를 모두 거의 균일하게 잃을 수 밖에 없다.
하지만, 우리는 일반적으로 중심과 떨어진 정도(x2+y2)와 같은 기존 feature를 non-linear하게 조합하여 활용하면 더 효과적인 구분이 가능할 것이라는 것을 알 수 있다. (아래 그림은 다른 방식을 사용한 것이지만, 원의 중심과 비슷하다.)
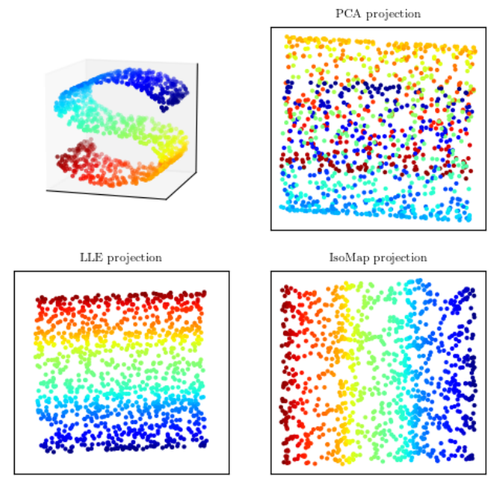
따라서, 우리는 기존 차원에서 선형으로 basis를 변경하는 것이 아니라 비선형으로 basis를 찾고 싶은 것이다. 기존 차원과 비교했을 때 비선형의 basis를 통해서 만들어지는 차원을 manifold라고 하며, 아래 왼쪽 위와 같은 manifold를 발견만 한다면, Dimensionality reduction을 기존 linear 방식과 비교했을 때 더 효과적으로 수행할 수 있다.
자 그렇다면 이 또한 어떻게 수학적으로 표현할 수 있을까? 이전에 썼던 Maximum Variance 방식을 이용할 것이다. 우선 우리가 data(x)를 non-linear 공간으로 차원 이동시킨 값을 ϕ(x)라고 정의하고, ∑i=1Nϕ(xi)=0이 되는 상황이라고 가정을 해보자.(그렇지 않으면 굉장히 수식이 복잡해지기 때문에 우선 이렇게 가정을 할 것이다.)
이를 푸는 과정은 앞에서 살펴봤으니 정리를 하자면, 결국 다음과 같은 eigenvalue, eigenvector를 찾는 것이다.
Sˉui=λiui
하지만, 이를 푸는 것은 굉장히 곤혹스럽다. 왜냐하면, 우리는 모든 data에 대해서 차원 변환 함수인 ϕ를 적용해주어야 하기 때문에 연산의 복잡도는 급격하게 증가하게 된다. 따라서, 우리는 이를 차원 변환 함수 ϕ의 연산 과정을 효과적으로 줄이는 방법을 제시한다. 이것이 kernel 함수이다. 이는 앞 서 살펴봤었던, 🔗 5. Multiclass Classification의 Kernel Method와 동일하다. 간단하게 설명하자면, ϕ(xi)⊤ϕ(xj)의 결과와 동일한 κ(xi,xj)의 연산을 활용해서 총 2번의 차원 변환과 곱셈 연산을 두 개의 변수를 받는 하나의 함수로 대체한다는 idea이다. 이를 통해서, 연산 비용을 획기적으로 줄일 수 있다. 따라서, 우리는 기존 식에서 ϕ를 없애고, kernel 만으로 이루어진 형태로 바꿀 것이다.
자 이제 마지막으로 해줘야 할 것은 우리가 맨 처음 가정했던 ∑i∈[N]ϕ(xi)=0 부분이다. 사실 대게의 일반적인 변환에서는 이렇게 이동하는 것이 더 드물 것이다. 따라서, 우리는 강제로 평균을 0으로 맞춰주는 과정을 수행해야 한다. 평균이 0이 되는 차원 변환 함수를 ϕ~라고 하고, 이때의 Kernel Matrix를 K~라고 하자. 그렇다면, 우리는 아래와 같이 적용하면, 강제로 평균을 0으로 만들 수 있다.
우리가 PCA에서 마지막에 살펴본 Kernel PCA의 한계는 data마다 kernel 함수를 어떻게 적용해야할지를 알 수 없다는 것이다. 그래서, 이를 위한 여러 Heuristic 방법들이 존재하지만 항상 완벽할 수는 없다. 그렇다면, 이 ϕ를 스스로 학습하는 방법을 알아볼 것이다.
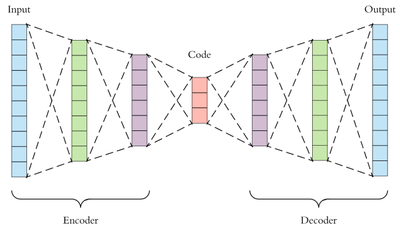
먼저, Encoding이란 data의 특징(feature)을 활용하여 이를 변형하는 것을 의미한다. 또한, 이 과정에서 중요한 것은 Encoding을 통해 얻은 결과를 이용해서 다시 원본 data를 복구할 수 있어야 한다.(복구하는 과정은 Decoding이라고 한다.) 이를 통해서, 우리는 압축을 하기도 하고, 관측 data로부터 숨겨진 feature를 추출하기도 한다. 여기서는 Dimensionality Reduction이 Encoding이라고 보는 것이다.
여기서 Auto Encoder는 Encoding을 통해서 Dimensionality Reduction을 수행하고, 이를 통해 얻은 결과로 원래 data를 Decoding할 수 있을 때가지 반복하는 것이다. 이 모든 과정의 결과로 원래 data와 Decoding된 data 간의 차이가 일정 임계값 이하로 떨어졌다면, 우리는 이제 이 Encoder를 ϕ의 대용으로 쓸 수 있다. 그리고 이 ϕ를 안다면, 이를 근사하는 kernel function도 찾을 수 있다.
이러한 방식은 굉장히 많은 분야에서 넓게 사용되고 있다. 이들을 간단하게 살펴보도록 하자.
CNN
결국 CNN은 너무 큰 image data를 처리하기 위해서 어쩔 수 없이 Dimensionality Reduction을 수행해야 한다. 따라서, 이를 감소시키기 위해서 Auto Encoder를 사용하여 true dimension을 찾을 수 있다.
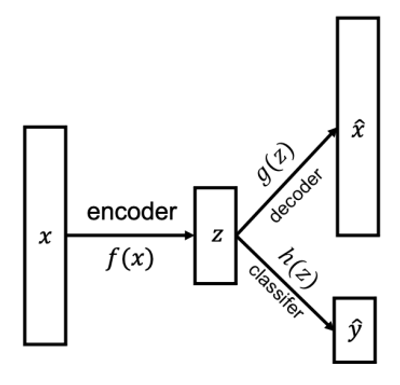
Semi-Supervised Learning
label이 존재하는 data는 굉장히 희귀하며, 이 labeling 비용이 매우 많이 든다. 따라서, label이 존재하는 data와 존재하지 않는 data를 동시에 활용하는 방법이 필요한 경우가 많다. 이때 auto encoding을 활용하게 되면, 일단 labeled, unlabeled data를 모두 활용하여 먼저 true dimension을 구한 뒤에 여기서 labeled data를 활용하여 classifier를 학습할 수 있다. 이것이 unlabed data를 활용하여 더 높은 적중률을 보여줄 수 있다.
그리고, 마지막으로 Auto Encoding의 성능을 올리기 위한 방법으로 Masking과 같은 data augmentation을 활용하는 것이다. 기존 data의 일부분을 masking하고도 실제 원본 data를 복구해낼 수 있도록 하는 것이다.


![[ML] 0. Base Knowledge](https://euidong.github.io/images/ml-thumbnail.jpg?imwidth=640)
Comments