Machine Learning은 주어진 data를 가장 잘 설명할 수 있는 pattern(Model)을 찾는 것이 목표라고 하였다. 그렇다면, "data가 가지는 여러가지 정보(feature)들 중에서 어떤 feature를 중점적으로 보고 이용할 수 있을까?" 그리고, "만약 여러 feature들이 서로 연관이 있다면 이를 연산의 최적화를 위해 이용할 수 있지 않을까?" 라는 접근이 가능하다. 여기서 Graphical Model은 이러한 관계를 시각적으로 표현할 수 있으며, 이를 통해서 연산 최적화에 대한 insight를 얻을 수 있다.
Relation
각 feature들 즉, Random Variable들 간의 관계는 크게 세 가지 종류가 있다.
Correlation(상관관계)
쉽게 생각하면 두 Random Variable이 있을 때, 서로가 값 추정에 영향을 준다는 것이다. 즉, 특정 Random Variable의 값이 관측되었을 때, Random Variable이 가지는 값의 범위가 제한되고, 확률이 변화한다.
즉, X와Y가 서로 Correlation이 존재한다면, P(X)=P(X∣Y)
그렇기에 두 Random Variable이 서로 독립(independence)이라면, Correlation이 존재하지 않는 것이다.
Causality(인과관계)
쉽게 Correlation과 헷갈릴 수 있지만, Causality는 원인과 결과가 나타나는 관계를 의미한다. 쉬운 예시로 X라는 사건과 Y라는 사건이 빈번하게 같이 발생한다고, 쉽게 X라는 사건이 Y의 원인이라고 말할 수는 없는 것과 같은 원리이다. 또한, 중요한 특징 중에 하나는 방향이 분명하다는 것이다. 원인과 결과는 대게 분리되기 때문에 원인이 되는 사건과 결과가 되는 사건이 분명이 구분된다. 결론적으로, Causality를 가지는 두 사건은 서로 Correlation이 있는 것은 자명하지만, Correlation이 존재한다고 Causality를 단정할 수 있는 것은 아니다. 즉, Correlation이 Causality를 포함하는 개념이다. 그렇기에 서로 독립이라면, Causality도 존재하지 않는 것이다.
Independence(독립)
위에 제시된 두 가지는 dependence 관계를 나타낸다. 이는 두 Random Variable의 값이 서로의 값에 영향을 전혀 주지 않음을 의미한다.
즉, X와 Y가 서로 독립하다면, P(X)=P(X∣Y),P(Y)=P(Y∣X)이다.
(결과적으로 Independence가 아니라면 최소한의 Correlation이 존재한다.)
이러한 관계를 어떻게 활용할 수 있을지를 고민해보자. 우리가 집중적으로 살펴볼 것은 Independence이다. 만약, 우리가 구하고자 하는 결과값(Y)가 존재할 때, 특정 feature(X1)가 서로 독립한다고 하자. P(Y∣X1)=P(Y)에 의해서 X1는 전혀 쓸모가 없는 정보임을 알 수가 있다. 이렇게 명확한 independence를 안다면 해당 feature를 Learning 및 Estimation에서 제거하는 것은 쉬울 것이다. 하지만, 우리는 이러한 관계를 명확하게 밝히기 어려울 때가 많다. 그렇다면 결국 우리가 Machine Learning을 통해서 구하고자 하는 식인 아래 식을 어떻게 하면 좀 더 최적화할 수 있을까?
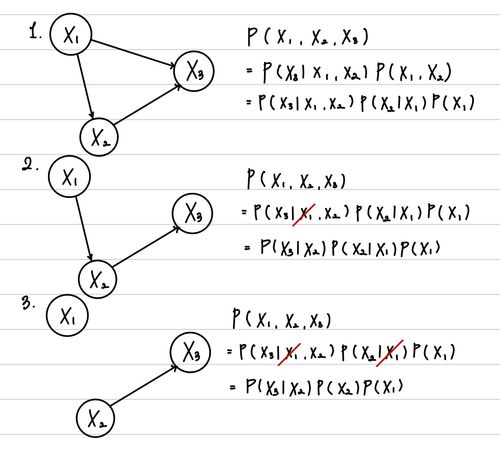
위에 제시한 Probability Chain Rule에 의해서 우리는 Joint Probability는 각각의 Random Variable 의 Conditional Probability라고 할 수 있다. 그렇다면, 우리는 Random Variable이 N개 있고, 각 Random Variable의 dimension이 L이라고 할 때, 다음과 같아짐을 알 수 있다.
LN×LN−1×⋯×L1=O(LN)
이러한 연산을 어떻게 하면 좀 더 최적화할 수 있을까? Hint는 Conditional Probability 각 각의 변수의 양을 줄이는 것이다. 우리가 어떤 관계가 있을 때, 이 Random Variable의 갯수를 줄일 수 있을까? 바로 변수 간 Conditional Independence가 이에 대한 해답을 제시한다.
Conditional Independence
Conditional Independence는 Conditional Probability처럼 특정 정보(다른 Random Variable의 값)가 주어졌을 때, 두 Random Variable이 서로 독립이라는 것이다.
쉽게 예를 들어 설명한다면, "과음"과 "빨간 얼굴" 사이의 관계라고 할 수 있다. 일반적으로 우리는 "빨간 얼굴"인 사람이 "과음"을 했을 것이라고 판단할 것이다. 즉, "빨간 얼굴"과 "과음" 사이에는 관계가 존재한다(dependency). 하지만, "혈중 알코올 농도"라는 정보가 주어진다면 어떨까? "혈중 알코올 농도"가 주어진다면, 사실 "빨간 얼굴"은 더 이상 "과음" 여부를 판단하는 기준에 영향을 1도 주지 않을 것이다. 이때에는 "과음"과 "빨간 얼굴"은 independence하다. 우리는 이런 경우를 다음과 같이 표현할 수 있다.
과음⊥⊥빨간얼굴
과음⊥⊥빨간얼굴∣혈중알코올농도
즉, 확률에 적용하면 다음과 같다.
P(과음∣빨간얼굴, 혈중알코올농도)=P(과음∣혈중알코올농도)
여기서 우리가 하고 싶었던 것이 나왔다. 바로 "빨간 얼굴"이라는 Random Variable이 없어졌다. 즉, "과음"과 "빨간 얼굴" 사이의 관계 같은 것을 찾을 수 있다면, 우리는 계산 과정을 단순화할 수 있다.
즉, 이것이 우리가 Graph를 통해서 찾고자 하는 것이다.
Graphical Model
Graphical Model은 Graph를 이용해서 Random Variable들의 관계를 표현하고, 이를 통해서 Joint Probability를 계산하는 방법이다. Graph를 그리는 방법은 기본적으로 Random Variable 하나 하나가 Graph의 Node가 되고, 각 Node간의 관계가 Edge가 된다. 그런데, 이 관계가 Correlation이냐, Causality냐에 따라서 두 가지 종류로 나뉘게 된다. Correlation은 일반적으로 관계의 방향이 없기에 Undirected Graph로 표현하고, Causality는 관계의 방향이 있기에 Directed Graph로 표현한다. 이는 아래에서 더 자세히 다루도록 하겠다.
Markov Random Field(Undirected Graphical Model, Correlation)
Markov Random Field(MRF)라고 불리며, Correlation를 표현한 Graph이다. 각 Node는 Random Variable을 의미하며, Edge는 Correlation를 의미한다. 즉, 두 Node가 Edge로 연결되어 있다면, 두 Random Variable은 Independence하지 않다는 것이다.
여기서 중요한 것은 Random Variable을 대표하는 Node와 Correlation을 대표하는 Edge이기 때문에, Graph G=(V,E)에서 Random Variable의 집합 X={X1,X2,⋯,X∣V∣}이고, {1,2,⋯,∣V∣}가 주어질 때 반드시 아래에 제시된 Markov Property들을 만족해야 한다.
Pairwise Markov Property
인접하지 않은 Node 두 개는 다른 모든 Node가 주어질 때 conditionally independent하다.
(아래에서 \는 포함하지 않는다는 의미이다.)
Xi⊥⊥Xj∣XS\{i,j}
Local Markov Property
한 Node에 인접한 모든 Node(Neighbors)가 주어질 때, 해당 Node는 다른 모든 Node와 conditionally independent하다.
(아래에서 Ni는 Node i와 인접한 모든 Node를 의미한다.)
Xi⊥⊥XS\Ni∣XNi
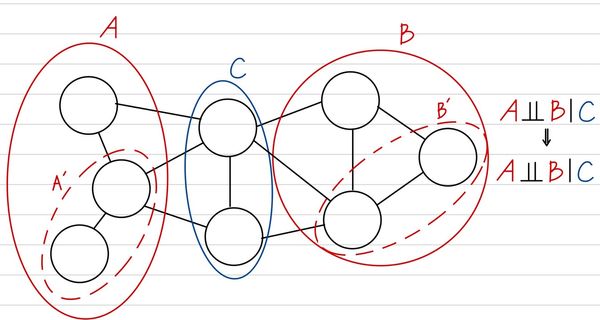
Global Markov Property
만약, Node들의 Subset으로 이루어진 A,B가 특정 subset C가 주어질 때, 서로 conditionally independent하다면, A,B에 속하는 어떤 subset이라도 서로 independent하다.
(subset간의 conditionally independent를 확인하기 위해서는 특정 Subset들간에 이어지는 모든 경로를 차단할 수 있는 subset이 있는지를 확인한다.)
XAXsubset of A⊥⊥XB∣XC⊥⊥Xsubset of B∣XC
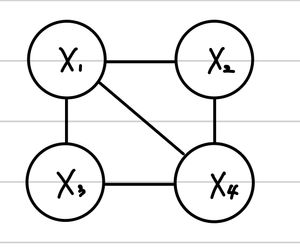
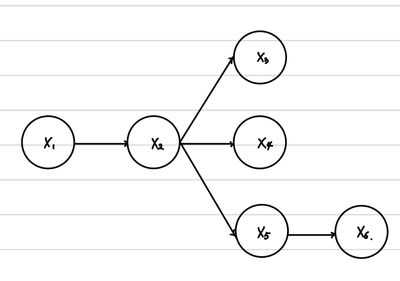
따라서, 우리는 이전 그림에서 Conditional Independence를 활용할 수 있다. X1,X4의 경우 다른 모든 Random Variable과 correlation이 존재하지만, X2,X3의 경우 X1,X4만 알면 된다. 즉, X2⊥⊥X3∣X1,X4이다. 따라서, 우리는 이 관계를 확률 식에서 녹여낼 수 있다.
또한, 우리는 Graph를 통해서 Joint Probability를 다음과 같이 정의할 수 있다.
P(∩i=1NXi)=Z1C∈C∏ψC(∩Xj∈CXj)
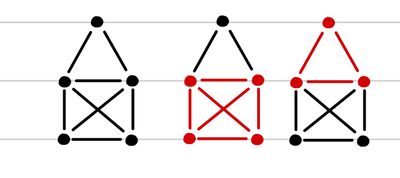
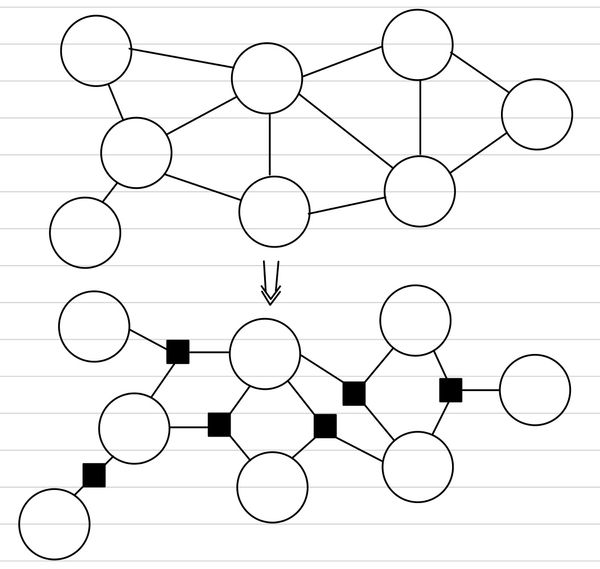
식이 다소 난해하다. 하나 하나 해석을 해보도록 하자. 먼저, P(∩i=1NXi)이다. 이는 Joint Probability를 표현하는 방법 중의 하나로 단순히 이를 정리하면, P(∩i=1NXi)=P(X1∩X2∩⋯∩XN)=P(X1,X2,⋯,XN)이다. 다음은 C와 C이다. 둘 다 아마 집합일 것이라는 것은 ∈ 기호 덕분에 알 수 있을 것이다. 그렇다면, 어떤 데이터를 담고 있는 집합일까? 이는 Random Variable들로 이루어진 부분 집합이다. 이를 Clique(C)라고 한다. Clique는 Graph에서 Node들의 부분 집합으로, Graph에서 Fully Connected Node의 집합을 의미한다. 이것이 가지는 의미는 사실상 하나의 Node로 합칠 수 있다는 것이다.(이를 Graph 상에서의 인수분해(factorization)라고도 한다.) Clique에 속하는 Node끼리는 서로 완벽하게 연결되어 있기 때문에 이 중에 하나의 Node라도 다른 Node와 연결을 가진다면, 이에 속하는 모든 Node가 이 관계로 연결된다는 것이다. 추가적으로 Clique들 중에서 다른 Clique에 속하지 않는 Clique들을 Maximal Clique(C)라고 한다. 아래 그림에서는 Maximal Clique를 빨간색으로 표기한 것이다.
마지막으로 ψ이다. 이는 Clique Potential Function로, 각 Clique의 Node(Random Variable)를 parameter로 사용하는 함수로 확률과 비슷한 성질을 가지지만 확률처럼 합이 1이 아닐 수도 있고, 값 자체가 음수일 수도 있다. 즉, 이를 구할 때에는 각 Random Variable의 경우의 수와 해당 경우의 상대적 확률로 이루어진 table을 작성하고, 이를 표현할 수 있는 함수를 찾아낸 것이 ψ이다. 대게의 경우 ψ는 해당 Parameter로 이루어진 Condition Probability 또는 Joint Probability가 되는 경우가 많다. 하지만, 그렇지 않은 경우에도 ψ로 표현이 가능하다.(이에 대한 엄밀한 증명은 여기서 다루지 않을 뿐만 아니라 중요하지 않다.) 여기서 Z의 의미를 마지막으로 짚어보자면, 단순한 normalization이다. ψ가 운좋게도 Joint Probability, Conditional Probability로 쉽게 구해진다면 Z=1이다. 하지만, 그렇지 않을 경우에는 이들의 합이 1이 아니기 때문에 Normalization이 필요한 것이다.
이것이 바로 ψ를 확률 함수라고 부르지 않는 이유이다.
우리가 ψ를 확률 함수 형태로 표현하기 위해서는 Chordal graph(4개 이상의 Node로 이루어진 Cycle에서는 중간에 반드시 Cycle을 이루는 Edge가 아닌 Edge가 존재하는 Graph) 형태를 가져야 한다는 것이다. ψ가 확률 함수로 표현되지 않는다고 우리가 하고자 하는 일에 영향을 주지는 않으니 그런가보다 하고 넘어가도 무방하다.
여기서 우리는 factorization이라는 개념을 익혔고, 이것이 가능하기 위해서는 Chordal graph가 주어진 상황에서 Markov Property를 만족해야 함을 확인했다. 그리고, 우리는 이러한 factorization 형태를 좀 더 명확하게 나타내기 위해서 다음과 같은 형태로 표현하고, 이를 factor graph라고 정의한다. 따라서, 각 factor(인수)는 Maximal Clique 단위로 생성된다.
Bayesian Network라고 불리며, Causality를 표현한 Graph이다. 각 Node는 Random Variable을 의미하며, Edge는 Causality(원인(C) -> 결과(R))를 의미한다. 그렇기에 굉장히 명확하게 표현이 될 수 있다. 왜냐하면, P(R,C)=P(C∣R)P(R)임을 명백하게 드러낸다. 그렇기에 우리는 해당 Graph가 주어지는 순간 Joint Probability를 다음과 같이 유추할 수 있는 것이다.
이러한 점 때문에 Bayesian Network에서는 Cycle이 존재할 수 없다. 왜냐하면, Cycle이 존재한다는 것은 각 Random Varaible이 서로 원인과 결과가 되는 것이 때문에 사실상 하나의 사건이라는 의미를 내포하는 것이다. 그렇기에 이는 사실상 존재할 수 없다.
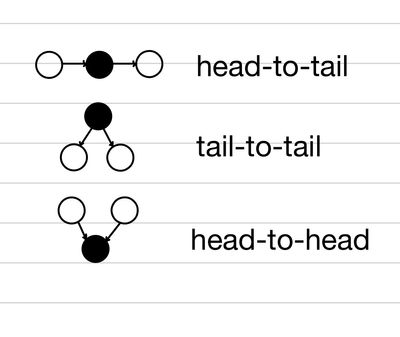
여기서도 마찬가지로 Conditional Independence를 찾을 수 있다. 뿐만 아니라 Marginal Independence에 대한 힌트도 얻을 수 있다. 이때 우리는 D-Seperation이라는 방법을 활용한다. 이를 위해서는 자신과 주변 2개의 Node가 이룰 수 있는 관계 3가지를 정의해야 한다.
head-to-tail
이 경우에는 X→Y→Z의 관계를 의미한다. 따라서, X와 Z는 Y가 주어질 때, 서로 Independent하다.
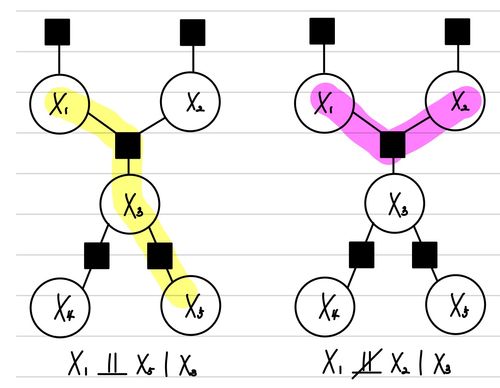
이 관계에서 중요한 것은 X,Z간 edge가 존재해서는 안된다는 점이다. 위의 관계를 활용하면, 인접한 관계에서의 Conditional Independence는 판별이 가능하다.하지만, D-Seperation을 통해서 이를 더 넓은 범위로 확장할 수 있다. 세 Node의 집합 A,B,C가 주어질 때, A⊥⊥B∣C이기 위해서는 다음 조건을 만족해야 한다.
A에서 B로 가는 경로가 하나 이상 존재한다.(여기서 경로는 방향을 신경쓰지 않고 연결 여부에 따라 결정한다.)
모든 경로에 대해서, C에 속하는 Node가 적어도 하나 head-to-tail 또는 tail-to-tail 관계를 중계할 수 있어야 한다.
모든 경로에 대해서, C에 속하는 Node는 head-to-head 관계를 중계하면 안되며, head-to-head 관계를 중계하는 Node의 자손이여도 안된다.
즉, A,B,C가 이러한 조건을 모두 만족할 때, 우리는 C가 A,B를 Block했다고 하며, A⊥⊥B∣C이다.
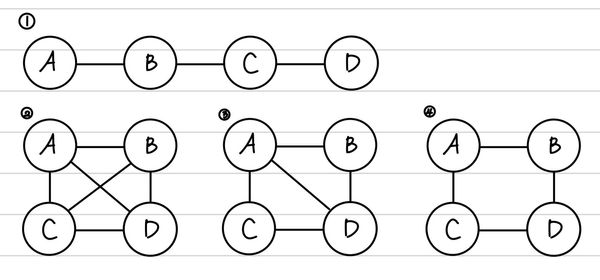
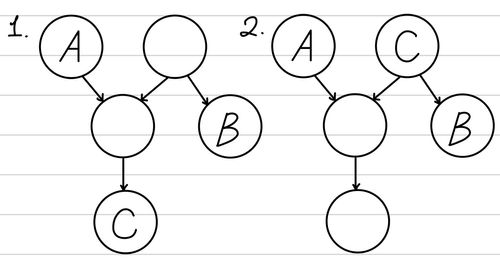
예를 들어 아래와 같은 두 경우를 예를 들어볼 수 있다.
왼쪽의 경우 C의 parent가 A에서 B로 가는 경로에서 head-to-head를 중계하고 있다. 따라서, A와 B는 Conditionally Independence를 만족하지 않는다. 반면, 오른쪽의 경우 C가 A에서 B로 가는 경로에서 head-to-tail 관계를 중계하고 있으므로, A와 B는 Conditionally Independence를 만족한다. 여기서 재밌는 점은 A와 B는 두 경우 모두 Marginal Independence를 만족한다는 점이다. 왜냐하면, A에서 B로 가는 경로가 순방향만으로는 이루어지지 않기 때문이다.
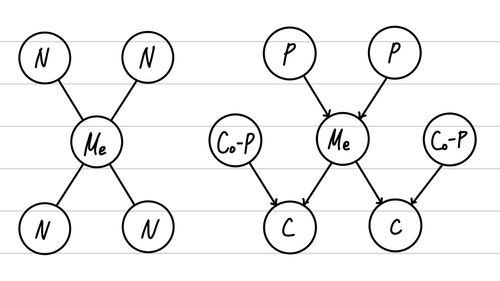
마지막으로, Bayesian Network도 factorization이 가능하다 A, B의 Causality가 P(A∣B)P(B)를 의미한다는 점을 활용해서 우리는 다음과 같은 형태로 정의하는 것이 가능하다.
즉, 초기 시작 점은 자신만을 가지는 factor를 가지고, head-to-head 관계는 하나로 통일하며, 나머지 관계(head-to-head, 등)는 별도로 factor를 분리한다. 즉, 다음과 같은 형태를 가진다.
1 🤔 Markov Blankets
23 Markov Blanket은 특정 Node에 대한 정보(관계)가 있는 모든 Node를 의미한다.
4 즉, 특정 Random Variable의 확률이 궁금하다면, 이 Markov Blanket만 가지면 된다.
5 그 중에서도 가장 작은 크기로 모든 필요한 정보를 담은 subset을 Markov Boundary라고 한다.
6 Markov Boundary는 Markov Random Field에서는 Neighbor이고,
7 Bayesian Network에서는 Parent, Child, Co-Parent이다.
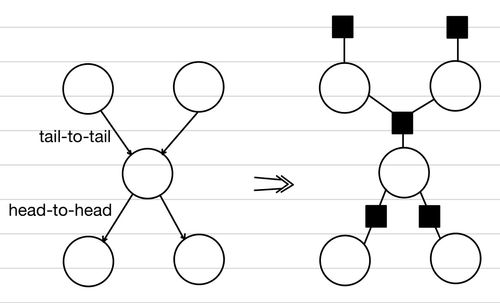
Factor Graph
앞 서 본 두 가지 Graph 표현 방법은 각 각 장단점을 가지고 있다.
Markov Random Field는 Joint Probability를 Potential이라는 임의의 변수를 통해서 추정하는 것이 가능하다. 따라서, 명확성이 떨이지지만, Conditional Independence를 파악하는 것은 더 분명하고 쉽다.
Bayesian Network는 Joint Probability를 명확하게 판별할 수 있다. 하지만, Conditional Independence를 판별하는 것이 더 어렵고 복잡하다.
이러한 장단점을 모두 살릴 수 있는 방법으로 제시된 것이 Factor Graph이다. 위에서 각 각 Factor Graph를 표현하는 방법에 대해서는 제시하였으므로 여기서는 다루지 않는다. Factor Graph는 근본적으로 Graph의 요소들을 인수분해(Factorization)하여 인수(Factor)로 분리해낸 것이다. 그렇기에 더 명확한 구분이 가능하다. 각 Node는 Factor와 기존 Node에 해당하는 값이 두 개 다 존재하고, Factor는 꽉 찬 네모, 기존 Node(Variable)는 비어있는 동그라미로 표현하는 것이 일반적이다.
그리고, 여기서는 Joint Probability를 다음과 같이 정의한다.
Variable Node는 {X1,X2,⋯,XN}이고, Factor Node가 {f1,f2,⋯,fM}일 때, fj와 이웃한 Variable Node의 집합을 Nj라고 하자.
P(X1,X2,⋯,XN)=j=1∏Mfj(∩X∈NjX)
이렇게 표현하는 것은 확실히 Markov Random Field에서는 명확하다. 하지만, Bayesian Network에서는 표현할 수 있는 정보를 어느정도 잃었다고 볼 수도 있다. 어차피 Conditional Probability인데, 다르게 표현한 것이기 때문이다. 하지만, 이를 이용하게 되면 기존에 문제였던 Conditional Independence를 쉽게 파악할 수 있다. 왜냐하면 Factor Graph에서는 Conditional Independence를 확인하기 위해서 해당 집합으로 이어지는 모든 경로에서 중간에 하나라도 Variable Node가 껴있는지만 확인해도 충분하다.
따라서, 앞으로의 과정에서는 Factor Graph를 Main으로 하여 설명을 진행하도록 하겠다.
Message Passing
우리는 앞의 Graph 표현을 통해서 Feature를 Factor로 압축하는 과정을 익혔다. 이 역시 엄청난 계산 효율을 가져온다. 하지만, 이를 더 효과적으로 활용할 수 있는 방법이 있다. 그것은 Message Passing 방법이다. 우선 우리가 해결하고자하는 문제를 정의해보자. 우리는 Joint Probability(P(X1,X2,⋯,XN))가 주어졌을 때, 다음 값을 구하고 싶을 수 있다.
Marginalization
Marginal Probability는 Joint Probability에서 구하고자 하는 Random Variable을 제외한 모든 경우의 수를 더한 것이다.
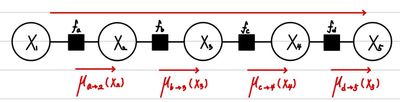
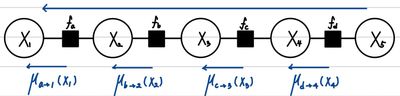
이것이 의미하는 바는 무엇일까? 이는 단순하게 순서를 바꾸어 재조합하는 것만으로 Computing을 줄일 수 있음을 보여줬다. 먼저, 앞의 ∑연산만 단독으로 할 때, L번의 연산이 필요하고, 뒤에 연속해서 나오는 3번의 ∑을 구하기 위해서는 결국 L3의 연산이 필요하다. 즉, L+L3의 합연산으로 marginalization 결과를 구할 수 있다는 것이다. 그렇기에 더 효율적인 연산이 가능한 것이다. 이는 특히 Graph의 중앙에 있는 값을 구할 때 더 도드라지게 나타난다. 전체 marginalization 결과를 나타내면 다음과 같다.
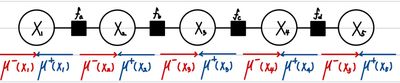
즉, 이전 Marginalization에서 계산했던 μfactor→variable(Xvariable)를 저장해서, 다음 Marginalization 연산 시에 사용할 수 있기 때문에 전체 Marginalization을 구하는데에도 더 빠른 연산이 가능하다. 이 방식은 역으로 진행하는 것도 가능한데 다음과 같다.
여기서 μ가 바로 Message를 의미한다. 즉, 우리가 마치 운동장에서 사람 수를 세기 위해서 앞 사람이 말한 수 + 1을 반복하면서 진행하는 것처럼 Message를 전달하며 전체 확률을 구해나가는 것이다. 이러한 방법을 Message Passing이라고 하며, 이 방법을 통해서 우리는 Marginal Probability를 더 효과적으로 구할 수 있다. 왜냐하면, μ−(Xi)를 구하기 위한 연산량이 (i−1)×L이라는 것과, mu+(Xi)를 구하기 위한 연산량이 (N−i)×L이라는 것을 알고 있다. 따라서, 각 각의 Marginalization을 구하기 위한 연산량이 LN−1에서 (N−1)L로 줄어들었다.
여기까지 우리는 Line으로 되어있는 가장 간단한 Factor Graph에서의 Sum-Product Belief Propagation을 알아본 것이다. 이제부터 우리는 더 복잡한 상황에서의 Belief Propagation(BP)을 살펴볼 것이다. Belief Propagation과 Message Passing은 대게 비슷한 의미로 사용되어 진다(일부는 Message Passing 후에 데이터를 가공하는 작업을 분리하고 이를 통합하여 Belief Propagation이라고 하기도 한다.)
Sum-Product Belief Propagation
합의 곱을 통해서 Marginal Probability를 구하는 방법으로, 앞 서 보았던 Linear Factor Graph 뿐만 아니라 Tree형태의 Factor Graph에서도 사용할 수 있다. 물론 Cycle이 존재하는 Factor Graph가 존재할 수도 있지만, 이 경우에 대해서는 특별한 알고리즘을 별도로 적용하는 것이 일반적이다. 따라서, 여기서는 Tree형태의 Factor Graph에서 일반적으로 적용할 수 있는 방법을 제시한다.
우선 아래 그림을 통해서 대략적인 이해를 해보도록 하자.
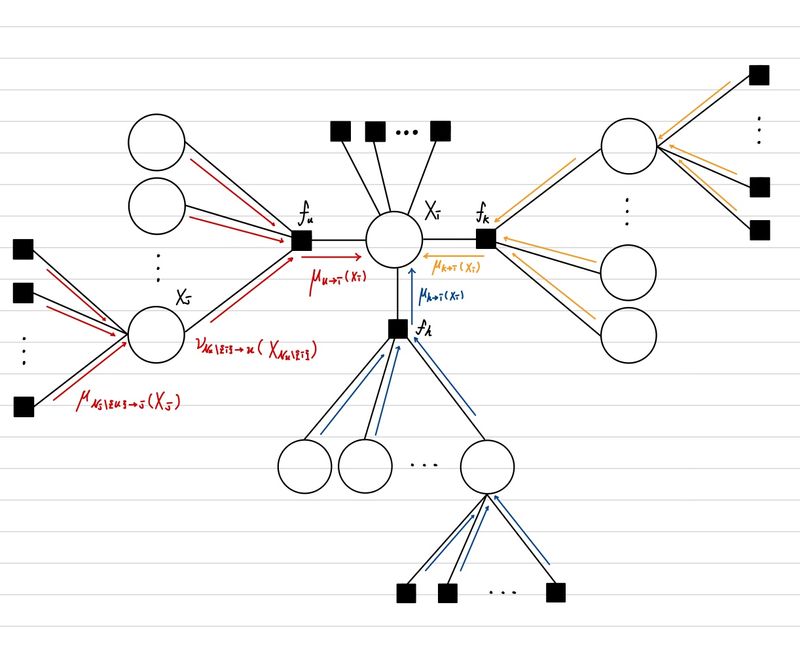
우리는 위에서 Line Factor Graph에서 어떻게 Marginal Probability를 어떻게 구하는지를 보았다. Tree 구조에서도 동일하게 결국 Marginal Probability를 자신과 이웃한 Factor Node들로 부터 전달된 Message의 곱이라고 할 수 있다. 단지 다른 점은 이웃한 factor가 복수 개라는 것이다.
(factor 또는 variable에 해당하는 Node 중에서 index가 i인 Node와 인접한 Node(Node i가 factor라면 variable, variable이라면 factor이다.)들의 index 집합을 Ni 라고하고, 값은 종류의 Node의 index를 모아둔 집합 I가 있을 때 XI={Xi}i∈I라고 하자.)
P(Xi)=p∈Ni∏μp→i(Xi)
그렇다면, 여기서 μp→i(Xi)를 각 각 어떻게 구할 수 있을까? 그러기 위해서 빨간색 부분을 자세히 봐보자.
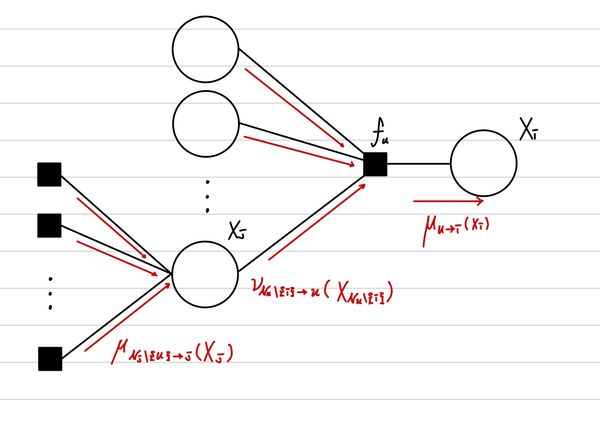
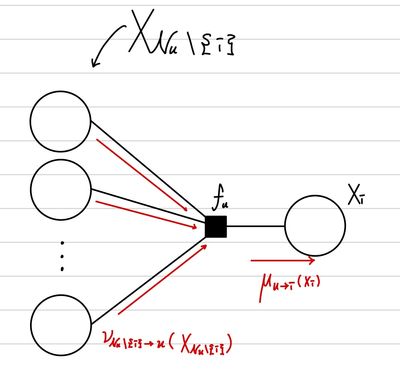
여기서도 기존 Linear Factor Graph와 다른 점은 Factor Node역시 여러 개의 Variable Node와 연결된다는 점이다. 이 부분만 떼어서 자세히 보면 다음과 같다.
그렇기에 이전 Variable Node로 부터 오는 Message들과 factor 값을 함께 곱하는 과정이 필요하다. 여기서, Varaible Node에서 factor Node로 오는 Message를 ν라고 정의한다면, 다음과 같이 표현할 수 있다. 여기서 주의할 점은 Factor Node와 이웃한 Variable Node 중에서 Message를 전달할 Variable Node는 연산에서 제외해야 한다는 점이다.
μu→i(Xi)=XNu\{i}∑fu(XN)j∈N\{i}∏νj→u(xj)
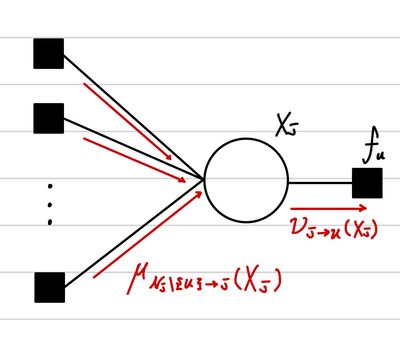
그리고 마지막으로 ν를 구하는 과정은 다음과 같다.
νj→u(Xj)=v∈Nj\{u}∏μv→j(Xj)
따라서, Marginal Probability(P(Xi))를 구하고자 할 때 우리는 Leaf Node에서 부터 시작해서 차례차례 값을 구하면서, μNi→i를 모두 구할 때까지 연산을 수행해야 한다.
1 🤔 Loopy Sum-Product BP
23 우리는 Sum-Product BP를 Tree에서만 쓸 수 있다고 제한하였지만,
4 사실 Cycle이 존재하는 Factor Graph에서도 동일한 BP를 사용할 수 있다.
5 하지만, 이 경우에는 비례 관계를 통해서 나타낼 수 밖에 없기 때문에
6 결과값에 대해서 100% 확신할 수는 없다.
Max Product Belief Propagation
Belief Propagation은 앞 서 살펴보았던 Marginal Probability를 구할 때에도 사용할 수 있지만, Maximization 문제를 풀 때에도 사용할 수 있다. 마찬가지로 가장 간단한 예시인 Linear Factor Graph를 가정해보자.
추가적으로 Max Sum Belief Propagation을 소개하겠다. 이는 Maximization 문제를 풀 때, log를 취한 결과도 동일하다는 점을 활용하여 문제를 푸는 것이다. 따라서, 다음과 같이 식이 조금 변화한다. 이 방식을 쓰면, 너무 작은 probability로 인한 문제를 피할 수 있다.
앞에서는 Graph를 통해서 연산 과정을 Optimization하는 방법을 알아보았다면, 여기서는 실제 관측 data를 이용해서 어떻게 Graph를 구조화할 수 있는지에 대해서 알아볼 것이다. 이를 수행하기 위해 많은 Algorithm이 존재하지만 가장 기본이 될 수 있는 Algorithm인 Chow-Liu Algorithm만 살펴보도록 하겠다.
Chow-Liu Algorithm
제일 먼저 구해야할 것은 Joint Probability이다. 이는 Empirical distribution을 이용하여 구할 수 있다. 아래는 feature가 N개인 총 K개의 data가 있을 때, 다음과 같이 Joint Probability를 구한 것이다.
위와 같이 Joint Probability가 주어졌을 때, Chow-Liu Algorithm에서는 Second Order Conditional Probability(총 두개의 Random Variable로 구성된 Conditional Probability. 즉, Condtion도 하나이고, 확률을 구하고자 하는 변수도 하나이다.)와 Marginal Probability로 Graph를 가정하고 Bayesian Network를 구성한다. 이 경우에는 형태가 Tree 형태로 만들어지기 때문에 결론적으로 head-to-head 관계가 만들어지지 않는다.(각 각의 node는 하나의 parent만 갖기 때문이다.)
여기서 이제 우리는 다음과 같은 문제만 풀면 끝이다. Empirical distribution으로 구한 Joint Probability(p)와 우리가 추정한 Graph에서의 Joint Probability(p⊺)사이의 차이가 최소가 되도록 하면 된다. 이를 위해서 사용하는 것이 KL Divergence이다. 따라서, 우리가 구하고 싶은 Bayesian Network는 다음과 같이 구할 수 있다.
여기서 V는 node의 집합을 의미하고, E는 edge를 저장하며 각 tuple(i,j)는 (parent, child)를 의미한다. 그리고, Tree에서는 단 하나의 Node만 Root이고 parent가 없기 때문에 해당 Root만 marginal Probability를 가지는 것을 알 수 있다.
마지막 marginalization은 헷갈린다면, 해당 Posting의 Sum-Product BP 부분을 다시 보고오도록 하자.
자, 이제 우리가 얻은 결론은 다음과 같다. 결국, 최적의 Tree는 I(Xi,Xj)가 최대가 되는 Tree이다. I(Mutual Information)이 헷갈린다면, Information Theory 정리해놓은 Posting을 다시 보고 오자. 결국, Xi,Xj간의 모든 Mutual Information을 구해서 weighted graph를 구축한다음에 Kruskal Algorithm을 통해서 최적 Tree를 찾으면 되는 것이다.
따라서, 과정은 다음과 같다.
가능한 모든 (i,j) 쌍에 대하여 I(Xi,Xj)를 구하여, Weighted Graph를 구성한다.
Kruskal Algorithm을 수행한다.
weight의 내림차순으로 Edge를 정렬한다.
하나씩 Edge를 뽑으면서, Cycle이 생기는지 확인하여 생기면 버리고, Cycle이 생기지 않으면 Tree에 추가한다.(Cycle 여부는 동일한 Node가 두 개 다 존재하는지 확인)
모든 Node를 뽑았다면 종료하고, 그렇지 않다면 2번을 반복 시행한다.
이렇게 Graph를 만들게 되면, 우리는 Joint Probability를 이전에 배운 Optimization 방법을 통해서 쉽게 구할 수 있다. 그리고, 이를 Model에 직접 적용할 수 있다. 예를 들면, 우리가 Classification을 수행할 때이다.


![[ML] 0. Base Knowledge](https://euidong.github.io/images/ml-thumbnail.jpg?imwidth=640)
Comments