Intro
여태까지 ML을 수행할 수 있는 여러 가지 방법론을 살펴보았다. 그렇다면, 어떤 Model을 선택하고, 학습과 추정을 해야할지 결정해야 한다. 따라서, 여기서는 어떤 것이 좋은 Model이고, 각 Model 간에 어떻게 비교를 수행할 것인지 그리고 더 나아가 Model을 혼합하는 방법에 대해서 알아볼 것이다.
What is Good Model?
우리가 사람 image를 입력받아서 긴 머리를 가진 사람인지 여부를 판단하는 classifier를 만든다고 하자. 이때 어떤 Model이 좋은 Model이 될 수 있을까?
가장 쉽게 생각할 수 있는 Model은 Fully Connected Neural Network(FCNN)를 구성하는 것이다. 이를 위해서 Image의 각 pixel을 일렬로 줄 세워 입력할 수 밖에 없다. 하지만, 이는 pixel들 간의 인접 관계를 사용할 수 없게 한다는 단점 때문에 높은 성능을 내기가 어려웠다. 따라서, 이를 극복하기 위헤서 제시된 방법이 Convolutional Neural Network(CNN)를 사용하는 것이다. 이는 FCNN을 적용하기 이전에 Image에 Filter를 적용하여 특정 구간을 대표하는 값을 뽑아내서 더 효율적인 학습을 하는 것을 목표로 한다.(물론 더 자세히 다루면 Pooling Layer 등 더 자세한 설명이 필요하지만, 여기서는 자세히 다루지 않는다. 해당 글을 참고하도록 하자. 🔗 CNN(Convolutional Neural Networks) 쉽게 이해하기)
우리의 뇌에서도 Image를 인식하고 처리하기 위해서, color와 motion 그리고 윤곽 등을 따로 따로 처리한다고 한다. 즉, CNN은 이러한 Domain Knowledge를 활용한 훌륭한 예시 중 하나라고 할 수 있다. 즉, 여기서 말하고자 하는 바는 결국 모든 환경에서 최고의 성능을 보여줄 수 있는 Model은 없다는 것이며, Good Model은 우리가 하고자 하는 일에 따라서 Domain Knowledge를 충실하게 활용하여 최고의 성능을 낼 수 있는 Model이라고 할 수 있다.
1 🤔 Data Augmentation 2 3 Domain Knowledge를 활용하여 Model의 성능을 높일 수 있는 방법은 4 단순히 Model 자체를 바꾸는 것 뿐만 아니라 Domain Knowledge를 바탕으로 5 Data를 추가적으로 더 만들어내는 방법이 있다. 이러한 방법을 6 Data Augmentation이라고 한다. 7 8 Image data 같은 경우에는 원본 Image를 약간 회전시키거나 확대하거나 9 Noise를 주는 등의 작업을 하여 전체 데이터의 크기를 늘릴 수 있다. 10 11Text 같은 경우에는 동의어를 활용하여 문장 데이터의 크기를 효과적으로 12늘리는 것도 가능하다.

Comparison between Models
여기서 만약 우리가 얻을 수 있는 Model의 종류가 다양하다면 이들을 어떻게 비교하여 하나의 Model을 선택할 수 있을까? 이 역시 중요한 문제이다.
사실 우리가 학습했던 data를 그대로 평가할 때 사용하는 것은 굉장히 불공평하다고 할 수 있다. 우리가 만들고자 하는 Model은 일반적으로 어느 상황에 두어도 그리고 안본 data일지라도 올바르게 분류하기를 원한다. 즉, 우리의 Model이 Generalization을 수행할 수 있기를 바란다.
이러한 Model의 Generalization 성능을 측정하기 위해서 자주 사용되는 것이 Dataset을 Train과 Test set으로 나누는 것이다. 하지만, 이것도 부족할 때가 있다. 특정 Model이 특정 Train set에서만 성능이 높을 수도 있기 때문이다. 따라서, 우리는 Cross Validation이라는 방식을 도입한다. 이는 우리가 가진 dataset을 골고루 test와 train set으로 활용하는 방법이다. 즉, 여러 번의 training을 수행하며, test를 수행하기를 반복하는 것이다. 그리고, 이를 평균을 내서 전체적인 Model 성능을 평가하는 방법이다.
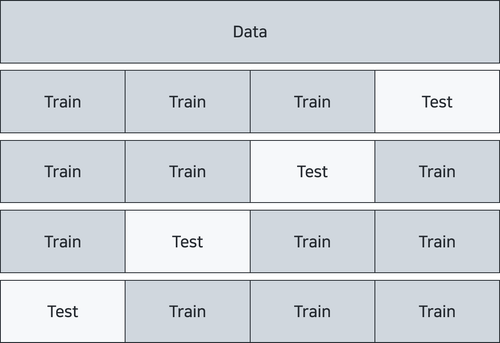
위와 같이 공평하게 k개로 나누는 방식을 k fold cross validation이라고 하며, 해당 예시는 인 경우이다. 즉, 위와 같이 Validation을 하기 위해서는 Model의 수가 개라고 할 때, 총 번의 Training과 Evaluation이 필요하다.
하지만, 여기서 또 간과한 사실은 hyperparameter가 각 model마다 큰 영향을 미친다는 사실이다. 즉, Hyper Parameter를 정하는 과정 역시 필요한데, 이는 각 각의 Model 내부에서 어떤 Hyper Parameter를 사용할지에 대한 합의가 필요한 것이다. 이를 확인하기 위해서 어쩔 수 없이 우리는 Training과 Evaluation을 수행해야 하며, 이를 위한 data를 별도로 분리해야 한다. 따라서, 우리가 가지는 dataset을 다음과 같이 세개로 나누어야 한다는 것이다.

여기서 더 정당하게 하고 싶다면, 아래와 같은 과정을 반복해야 한다.
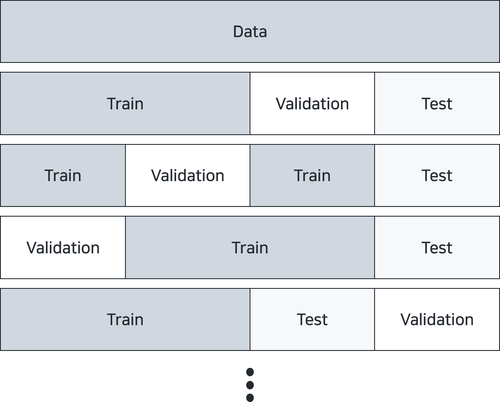
하지만, 이는 굉장히 비용이 커질 수 있다. validation set을 고를 때, 개가 필요하다고 한다면, 우리는 번의 Training과 Evaluation이 필요한 것이다. 굉장히 비용이 커지기 때문에 대게 validation set까지 cross validation하는 nested cross validation은 상황에 따라 사용되기도 하고, 사용되지 않기도 한다.
Combining Simple Models
좋은 Model을 만들 수 있는 방법 중에서 가장 쉽게 생각할 수 있는 것 중에 하나가 여러 개의 Model을 활용하는 방법이다. 쉽게 집단 지성을 활용한다고 볼 수 있다. 이러한 방식을 Ensemble(앙상블)이라고 부르고, 이를 활용할 수 있는 방법은 여러 가지가 있다.
- 서로 다른 여러 개의 Model, 또는 Hyperparameter만을 변경하거나 또는 feature를 다르게 변형하여 Model을 여러 개 생성하고 평균 또는 최댓값을 취하는 방법 (Voting)
- 여러 개의 Model을 혼합하지만, 각 단계에 따라서 Model을 선택하는 방법 (Stacking)
- dataset을 여러 번 sampling하여 각 각의 Model을 만들고, 각 Model의 결과를 평균 또는 최댓값을 취하는 방법 (Bagging, Pasting)
- 이전과는 달리 앞 서 진행한 Model의 결과를 반영하여 다음 Model에 적용하기를 반복하며, 여러 Model을 제작하고 취합하는 방법 (Boosting)
크게는 이렇게 3가지로 나눌 수 있다. 여기서 각각을 자세히 다루지는 않고, Boosting 방식 중에서도 많이 사용되는 방법 중에 하나인 AdaBoost에 대해서 좀 더 자세히 다뤄보도록 하겠다.
AdaBoost
Adaptive Boosting의 약자인 AdaBoost는 이름에서 볼 수 있듯이 반복적인 작업을 통해서 최종 Model의 성능을 높이는 것을 목표로 한다. 우선 Boosting 방법 자체가 동시에 Model을 학습시키는 것이 아니고, 순차적으로 학습시키면서 성능을 높이는 방법이다. 그렇다면, 우리가 이전 Model들의 학습 과정에서 다음 Model에게 넘겨줄 수 있는 특별한 정보는 무엇일까? 이는 바로 자신들이 잘못 분류한 데이터에 대한 정보이다. 자신들이 잘못 분류한 data들에게 더 높은 가중치를 부여하도록 하여 다음 Model에서는 이를 중심적으로 분류할 수 있도록 하는 방식으로 최종 Model의 성능을 높여보자는 것이 Idea이다.
그렇다면, 이것이 어떻게 가능할까? 매우 간단한 이진 분류기를 기반으로 이를 설명하도록 하겠다. 우리가 만약 특정 임계값()보다 작으면 -1, 그렇지 않으면 1이라고 분류하는 아주 간단한 분류기(weak classifier, decision stump)를 가지고 있다고 하자.
이제 우리는 이 간단한 분류기 T개를 합쳐서 복잡한 분류 문제를 해결할 분류기를 제작할 것이다. 이 때, 각 분류기는 다음과 같은 가중치()를 가지게 된다.
그렇다면, 우리는 위 식에서 어떻게 하면, 현명하게 를 결정할 수 있을까? 이에 대한 해답으로 AdaBoost는 이전 에 의해 발생한 error에 집중한다.
우선 의 Error()를 아래와 같다고 하자.
즉, 예측이 맞다면 error는 , 틀리다면 만큼 error가 증가한다.
여기서 우리는 현재 학습할 Model 이전까지의 Model의 하나의 데이터에 대한 Error를 라고 정의해보자.
다시 한 번 의 의미를 정의하면, 간단하게 이전까지의 Model의 합으로 만든 Model이 잘 분류했다면, 그렇지 않다면, 가 된다.
그렇다면, 계속해서 Error 식을 정리해보자.
여기서 Error를 가장 작게 할 수 있는 를 찾기 위한 방법은 각 각 다음과 같다.
- 식에서 가 바꿀 수 있는 것은 밖에 없다. 즉 를 조정하는 것이다.
즉, 는 이전 분류기()가 잘 분류했다면 , 그렇지 않다면 가 되는데, 이들의 합이 최소가 되도록 하는 임계값 를 찾는 것이다.
즉, 기존 분류기가 잘못 분류한 data에 대해서 더 중점적으로 분류할 수 있도록 가중치를 부여하여 다시 분류한다는 것이다. - Error를 에 대한 미분을 하여, 0이 되도록 하는 를 찾으면 된다. 이 과정은 다음과 같다.
여기서 를 자세히 보면, 분모는 decision stump의 최대 Error이고 분자는 현재 decision stump의 Error를 의미한다. 이것이 직접적으로 에 영향을 미치는 것이다.
따라서 이르 조금 더 정리하자면 다음과 같다.
라는 것은 사실 의 성능이 선택지 두 개지 하나를 Random하게 고르는 경우의 확률 보다 못하다는 것이다. 이 경우에 를 음수로 설정하여 적용하는 것이 반대로 확률을 적용하는 것이고, 이것이 전체 성능을 높일 수 있기에 타당하다.
만약, 성능이 딱 라면, 더 이상 개선의 여지가 없어진다. 즉, 를 0으로 설정하여 적용하게 되면, 이 된다. 즉, 더 이상의 Model 중첩은 무의미하다는 것을 의미하므로 해당 단계에 도달하면 학습을 중단한다.
일반적인 경우로, 새롭게 만든 분류기가 기존 분류기()를 보완할 만큼 잘 예측을 하고 있기에 를 양수로 설정하여 적용한다.
가 0에 가까워지면, 즉, 가 모든 data를 정확하게 분류한다면, 사실상 기존 분류기들은 더 이상 의미가 없다. 하나의 로 완벽하게 분류되는 문제였기 때문이다. 즉, 가 된다.
Decision Tree
앞 선 AdaBoost에서는 Decision Stump를 다루었지만, 더 다양한 분류기를 이용해서 Decision Tree를 구성하는 것도 가능하다. 실제 Stacking 또는 Bagging 등의 작업을 할 때에는 단순한 Decision Stump의 합 같은 형태가 아니라 Tree형태로 구성되는 경우가 많다(Decision을 할 때마다 가지치기를 하며 나뉘는 형태). 그리고 실제로도 이 형태가 인간의 사고 과정도 매우 유사하다. 따라서, 대게의 경우 성능도 좋은 뿐만 아니라 직관적이기 때문에 이러한 방식을 사용해서 여러 Model을 혼합하는 경우도 있다. 이 안에서 Decision을 수행할 때 복잡한 Deep Learning을 수행할 수도 있고, 단순하게 Decision Stump를 사용할 수도 있는 것이다.
그렇다면, 이러한 Decision Tree를 어떻게 학습하는 게 좋을지를 조금만 살펴보도록 하겠다. 가정을 하나 해보자. 우리가 분류하고자 하는 Category가 10개이고, feature가 100개이다. 이때, 어떤 Feature를 이용한 어떤 Model을 사용한 것을 우선으로 적용해야할까? 이것이 사실 가장 중요한 문제이다. 이를 해결하기 위해서 여러 알고리즘(ID3, CART, 등)이 제시되었다. 하지만, 결국 핵심은 각 각의 단계에서 데이터를 가장 적절하게 나누는 것이 중요한 것이다. 따라서, Model(f)에 대해서 얻을 수 있는 정보의 양(IG, Information Gain)이 많을 수록 좋은 Model이라고 칭하는 것이다. 이를 식으로 표현하면 다음과 같다.
여기서, 또 그렇다면, I는 무엇인지 궁금할 수 있다. 이는 Impurity(정보의 혼탁도)를 의미하며, 이를 표현하는 지표는 아래와 같은 것들이 있다.
- Gini Impurity
- Entropy
- Classification Error
위 중에서 우리가 🔗 ML Base Knowledge(Information Theory)에서 다루었던 Entropy에 기반한 방법이 가장 즐겨서 사용되어진다.
즉, Entropy에 기반한 설명을 하자면, 우리는 IG(정보 획득량)를 최대화하기 위한 선택을 하게 되면, 해당 결정의 Child들은 적은 Entropy를 가지게 되고 이 과정을 반복해 나가면서 최적화를 수행하는 것이다.
즉, Decision Tree를 생성할 때에는 여러 가지 feature와 Model을 적용하며 각 Model이 가지는 IG를 기반으로 하여 Tree의 Root에서부터 Model을 선택하며 내려오는 것이다.
Cutting down a Compex Model
또한, 좋은 Model을 만들기 위해서 아이러니하게도 일부 정보를 삭제하는 것이 도움이 될 때가 있다. 대게 Deep Learning 환경에서 많이 발생하는 경우인데, over fitting으로 인한 문제를 해결하기 위해서 일부 edge를 제거하는 dropout을 수행한다. 이러한 방법은 over fitting을 방지할 뿐만 아니라 학습의 속도 역시 개선할 수 있기 때문에 자주 사용되어진다. 실제로 model의 성능이 증가할 수 있는지에 대해 다룬 논문이 별도로 있으니 참고할 수 있다면 해보도록 하자. 만약 시간이 된다면 이에 대해서도 다룰 수 있도록 하겠다.
- Frankle, Jonathan, and Michael Carbin. "The lottery ticket hypothesis: Finding sparse, trainable neural networks." ICRL 2019
Reference
- Tumbnail : Photo by Markus Winkler on Unsplash
- 🔗 CNN(Convolutional Neural Networks) 쉽게 이해하기

![[ML] 0. Base Knowledge](https://euidong.github.io/images/ml-thumbnail.jpg?imwidth=640)
Comments