Intro
주어지는 data에 항상 feature, label이 정확하게 매칭되지는 않는다. 이럴 경우 우리는 각 data에 대한 label과 주어진 data와 label을 잘 설명할 수 있는 probability distribution을 모두 구해야 한다. 여기서 label과 probability distribution을 동시에 구하기 위해서는 어떻게 해야할지에 대한 방법 중에서 대표적인 EM Algorithm에 대해서 살펴보도록 하겠다.
Problem
여태까지 우리가 살펴봤던 supervised learning에서는 학습(learning) 시에는 feature와 label이 모두 동시에 주어지고, 예측/추론(inference)을 수행할 때에는 feature만 존재하는 data가 주어졌다. 따라서, 학습 시에 feature 정보들을 특정 pattern에 녹여냈을 때, label값을 얻는지를 확인할 수 있었다. 하지만, label이 주어지지 않은 data를 학습시킬 때에는 어떻게 해야할까? 우리는 label이 있어야 해당 data가 가진 실제 결과값을 알고 probability distribution을 얼마나 수정할지를 알 수 있었다. 하지만, 이 값을 모르니 probability distribution을 만들 수 없다. 정확한 probability distribution이 있다면, 반대로 label을 생성하는 것도 가능할 것이다. 하지만, 우리는 아무것도 알 수 없다.
이렇게 답답한 상황에서 우리는 다음과 같은 아이디어를 발상해낼 수 있다. 만약, 대략적인 label을 안다면, 이것을 이용해서 최적의 확률 분포를 찾고, 이 확률 분포에 맞는 label을 다시 생성하고 이를 기반으로 다시 확률 분포를 찾는다면 어떨까? 이렇게 반복하면 꽤나 그럴싸한 분포를 만들 수 있지 않을까? 이 과정을 예를 들자면, 다음과 같다.
각 기 다른 나라(label)의 동전 3종류(500원, 100cent, 100엔)를 구분하고 싶다고 하자. 이때, 알 수 있는 정보는 무게(feature) 밖에 없다고 가정하겠다. 이때 우리는 어떻게 구분할 수 있을까? 우리가 길 거리에서 무작위로 동전을 수집했다고 하자. 각 동전은 흠집도 있을 것이고 공장마다 조금씩 무게가 차이있을 수 있다. 그 결과 다음과 같은 분포가 나왔다고 하자.
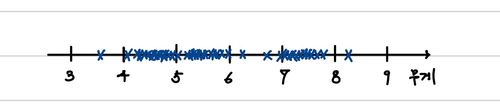
그래서 우리는 확률 분포가 아마 Gaussian distribution이라고 생각할 것이다. 따라서, 임의의 Gaussian Distribution을 따르는 세 개의 분포를 아래와 같이 가정해보는 것이다.
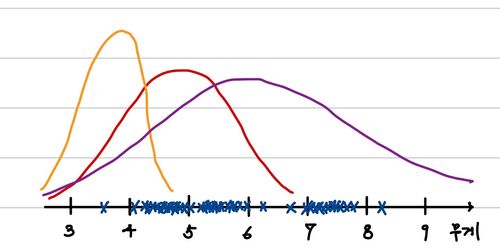
그렇다면, 우리는 이 분포에 따라 가장 적절한 label을 생성할 수 있다. 아래와 같이 생성할 수 있다.
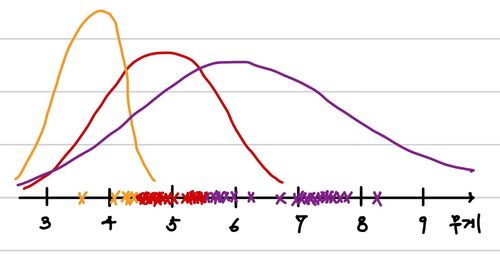
그러면 결과적으로 우리는 다음과 같은 label된 data를 갖게 되는 것이다.
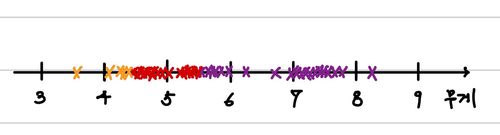
이렇게 labeling data를 이용해서 우리는 더 효과적인 확률 분포 변수를 찾아보면 아래와 같이 이전과는 사뭇 다른 분포를 가진다는 것을 알 수 있다.
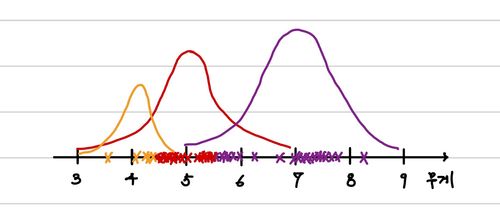
결과적으로 해당 분포가 이전에 임의로 추정했던 분포보다 더 적절하다는 것을 알 수 있다. 이 과정을 계속해서 반복하면 어떻게 될까?
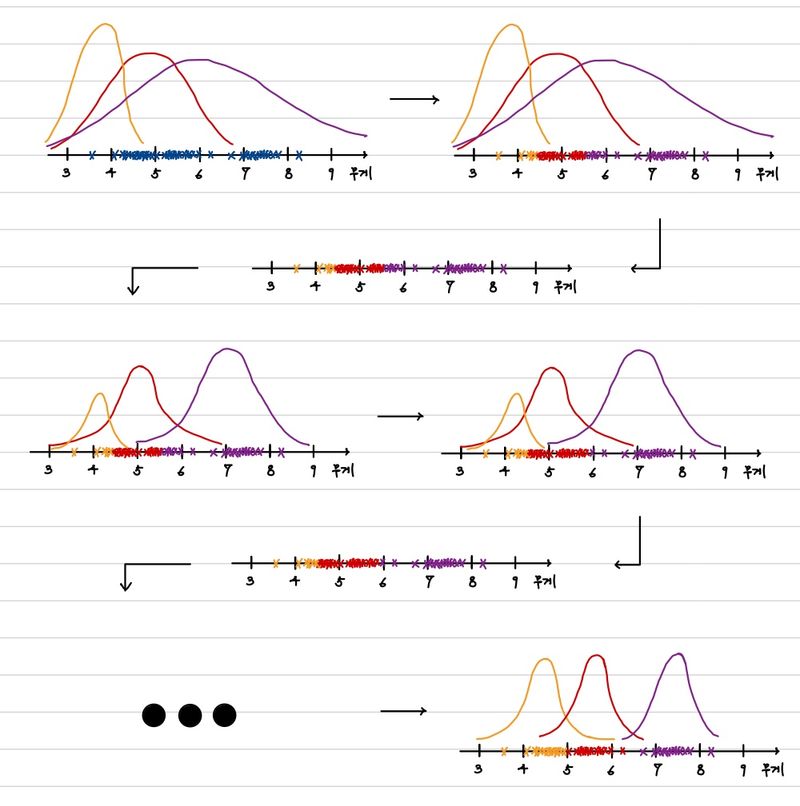
반복을 통해서 우리는 그럴싸한 확률분포를 습득했다. 대략 머릿속으로는 그럴 수 있을 것 같다는 생각이 들 것이다. 그렇다면, 이것이 어떻게 가능하며 수학적으로 표현이 가능할까? 이를 이제부터 자세히 알아보도록 하겠다.
Base Knowledge
본론으로 들어가기에 앞 서 우리는 두 가지 정의를 알아야 EM Algorithm을 증명하고 설명할 수 있다.
- Jensen’s Inequality
- Gibb's Inequality
이 두 가지를 모두 안다면 바로 다음으로 넘어가는 것이 좋다. 하지만, 알지 못한다면 이 정의에 대해서 먼저 알아보고 가도록 하자.
Jensen’s Inequality
일반적으로 우리는 다음 성질을 만족하는 집합을 Convex set이라고 한다.
λx+(1−λ)y∈C,∀x,y∈C and ∀λ∈[0,1]
즉, 집합에서 random으로 고른 두 수 사이의 수도 집합에 포함되는 집합이라는 것이다. convex set이라고 불리는 이유는 결국 이러한 집합을 2, 3 차원상에 그려보면 볼록하게 튀어나오는 형태라는 것을 알 수 있기 때문이다.
또한, 아래와 같은 조건을 만족하는 함수(f)를 Convex function이라고 한다.
f(λx+(1−λ)y)≤λf(x)+(1−λ)f(y),∀x,y∈C(Convex set) and ∀λ∈[0,1]
아래로 볼록한 함수에서는 위와 같은 과정이 너무나 당연하게도 성립한다. 사잇값의 함수값보다 함수값의 사잇값이 더 크기 때문이다.
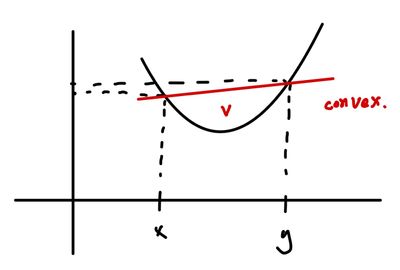
반대로 concave(위로 볼록) 함수인 경우에는 반대로 다음과 같이 정의된다.
f(λx+(1−λ)y)≥λf(x)+(1−λ)f(y),∀x,y∈C(Convex set) and ∀λ∈[0,1]
여기서 Jensen's Inequality는 다음과 같은 수식이 convex에서 성립한다는 것이다.
E[f(X)]≥f(E[X])
convex function에서는 어찌보면 당연해보인다. 그렇지만 이는 EM Algorithm에서 토대로 사용되는 아이디어이기 때문에 반드시 기억하자. 반대로 Concave function인 경우에는 다음과 같다.
E[f(X)]≤f(E[X])
Gibb's Inequality
KL divergence 식에 Jensen's Inequality를 적용하여 KL divergence가 항상 0보다 크거나 같고, KL divergence가 0이 되기 위해서는 두 확률분포가 같아야 한다는 것을 증명한 것이다.
이에 대한 증명을 간단하게 하면 다음과 같다.
KL(p∣∣q)∴KL(p∣∣q)=i∑pilogqipi=−i∑pilogpiqi=Ep[−logpiqi]≥−logEp[piqi](∵Jensen’s Inequality)=−logi∑pipiqi=−log1=0≥0
EM Algorithm
우리는 parametric estimation 방법을 사용하기 위해서 다음과 같은 Likelihood를 계산했다.
L(θ)L(θ)=logp(D∣θ)=logx∈D∏p(x∣θ)=x∈D∑logp(x∣θ)
그렇지만 우리가 이 값을 구하는 것이 어렵다는 것을 위에서 제시했다. 따라서, 이를 다음과 같이 바꿔서 풀어보자는 것이다.
L(θ)=x∈D∑logp(x∣θ)=x∈D∑log∫z∈Kp(x,z∣θ)dz
이렇게 바꾸게 된다고 무슨 이득이 있을까? 단순히 식이 더 복잡해보인다. 하지만, 이 식을 다음과 같이 바꿀 수 있다.
L(θ)=x∈D∑logp(x∣θ)=x∈D∑log∫z∈Kp(x,z∣θ)dz=x∈D∑log∫z∈Kp(x,z∣θ)p(z∣x,θ′)p(z∣x,θ′)dz=x∈D∑log∫z∈Kp(z∣x,θ′)p(z∣x,θ′)p(x,z∣θ)dz=x∈D∑logEz∣x,θ′[p(z∣x,θ′)p(x,z∣θ)]≥x∈D∑Ez∣x,θ′[logp(z∣x,θ′)p(x,z∣θ)](∵Jensen’s Inequality)=F(pz∣x,θ′,θ)
이를 통해서 우리는 아래와 같은 과정을 수행해볼 수 있다.
L(θ)−F(pz∣x,θ′,θ)=x∈D∑logp(x∣θ)−x∈D∑{∫z∣x,θ′p(z∣x,θ′)logp(z∣x,θ′)p(x,z∣θ)}=x∈D∑logp(x∣θ)−x∈D∑{∫z∣x,θ′p(z∣x,θ′)logp(z∣x,θ′)p(z∣x,θ)p(x∣θ)}=x∈D∑logp(x∣θ)−x∈D∑{∫z∣x,θ′p(z∣x,θ′)logp(x∣θ)+∫z∣x,θ′p(z∣x,θ′)logp(z∣x,θ′)p(z∣x,θ)}=x∈D∑{∫z∣x,θ′p(z∣x,θ′)logp(z∣x,θ)p(z∣x,θ′)}=x∈D∑KL(pz∣x,θ′,pz∣x,θ)
우리가 원하는 것은 결국 해당 값의 minization이다. 따라서, 우리는 모든 x에 대해서 KL-divergence의 최솟값을 구해야 한다(모든 사건은 독립이기 때문이다). KL-divergence는 0과 같거나 큰 수이고, KL-divergence는 pz∣x,θ′=pz∣x,θ일 때, 0이므로 이를 만족할 수 있는 값을 찾는 것이 중요하다.
따라서, 우리는 다음과 같은 insight를 얻을 수 있다.
- F(pz∣x,θ(t−1),θ(t))≤L(θ(t)) 아래 식에 의해서 이를 증명할 수 있다.
F(pz∣x,θ,θ(t))≤L(θ(t))(∵Jensen’s Inequality)
- L(θ(t))=F(pz∣x,θ(t),θ(t)) 바로 위에서 살펴보았 듯이 pz∣x,θ′=pz∣x,θ일 때, 등식이 성립한다. (Gibb's Inequality)
- F(pz∣x,θ(t),θ(t))≤F(pz∣x,θ(t),θ(t+1))
여기서 θ(t+1)은 다음과 같이 구할 수 있다.
θ(t+1)=argmaxθF(pz∣x,θ(t),θ)
- F(pz∣x,θ(t),θ(t+1))≤L(θ(t+1))
이는 1번과 동일한 식이다.
- L(θ(t))≤L(θ(t+1))
결론적으로, 5번에 의해서 우리는 매단계가 이전보다 같거나 크다는 것을 알 수 있다. 또한, 각 단계를 차례대로 설명한다면 다음과 같다.
- 이전 확률과 현재 parameter의 추정치를 이용해서 구한 F(pz∣x,θ(t−1),θ(t))는 θ(t))≤L(θ(t))보다 작다는 것을 Jensen's Inequality에 의해서 알 수 있다.
- 우리는 이제 F(pz∣x,θ,θ(t))를 최대화하기 위해서 pz∣x,θ를 pz∣x,θ(t)로 업데이트 한다. 그렇다면, 이 결과는 앞 서 보았듯이 이 값은 L(θ(t))와 동일한 결과를 갖는다.
- 여기서 우리가 얻은 F(pz∣x,θ(t),θ)를 최대화할 수 있는 θ(t+1)를 구한다면, 이는 당연하게도 F(pz∣x,θ(t),θ(t)) 보다 크다.
- 이렇게 얻은 새로운 parameter에 의한 결과는 역시 당연하게도 1번과 같은 결론에 도달하게 된다.
- 결국 우리는 1~4번 까지의 과정을 거치면서 L(θ)를 계속해서 증가시킬 수 있다.
결국 우리가 해야할 것은 다음값을 매차시마다 구하는 것이다.
θ(t+1)=θargmaxF(pz∣x,θ(t),θ)
이를 위해서 먼저 우리는 F(pz∣x,θ(t),θ)의 식을 좀 더 정리해볼 것이다.
F(pz∣x,θ′,θ)=x∈D∑Ez∣x,θ′[logp(z∣x,θ′)p(x,z∣θ)]=x∈D∑{∫z∣x,θ′p(z∣x,θ′)logp(z∣x,θ′)p(x,z∣θ)}=x∈D∑{∫z∣x,θ′p(z∣x,θ′)logp(x,z∣θ)+∫z∣x,θ′p(z∣x,θ′)logp(z∣x,θ′)1}=x∈D∑{∫z∣x,θ′p(z∣x,θ′)logp(x,z∣θ)+H(pz∣x,θ′)}
위 식에서 우리는 argmaxθF(pz∣x,θ(t),θ)를 구하기 위한 과정에서 H(pz∣x,θ′)는 필요없다는 것을 알 수 있다.
Q(θ;θ′)=F(pz∣x,θ(t),θ)−H(pz∣x,θ′)=x∈D∑{∫z∣x,θ′p(z∣x,θ′)logp(x,z∣θ)}=x∈D∑{Ez∣x,θ′[logp(x,z∣θ)]}
그 결과 우리는 다음과 같은 결론을 내릴 수 있다.
θ(t+1)=θargmaxQ(θ;θ(t))=θargmaxx∈D∑{Ez∣x,θ(t)[logp(x,z∣θ)]}
따라서, 우리는 이를 효과적으로 구하기 위해서 EM Algorithm을 다음과 같이 정의하고, 단계에 따라 수행한다.
- Expectation Step
앞에서 제시한 Q(θ;θ(t))의 식을 구하는 단계이다. 즉, 변수를 θ 외에는 모두 없애는 단계이다. Expectation 단계라고 부르는 이유는 Q(θ;θ(t))가 ∑x∈D{Ez∣x,θ′[logp(x,z∣θ)]}와 같이 Expectation의 합의 형태로 표현되기 때문이다.
이를 좀 더 쉽게 표현하자면 다음과 같이 말할 수도 있다. 이전 parameter θ(t)가 주어졌을 때, 각 데이터에 대한 latent variable z의 확률을 구하는 것이다. 즉, p(z∣x,θ(t))를 구하는 것이다.
- Maximization Step
이제 앞 서 구한 Q(θ;θ(t))를 θ에 대해 최대화하여, θ(t+1)를 구하는 단계이다.
이것이 EM Algorithm의 본질이다.
그래서 앞 선 Clustering에서 살펴보았던 것처럼 EM Algorithm을 다음과 같이 정의할 수도 있는 것이다.
- 초기 parameter θ(0)를 설정한다.
- 이를 기반으로 data가 해당 분포에서 z일 확률을 구한다.
- 구한 확률을 바탕으로 해당 확률과 data를 잘 표현할 수 있는 새로운 parameter θ(t+1)를 구한다.
- 2, 3번 과정을 parameter가 일정 수준에 수렴할 때까지 반복한다.
Reference

![[ML] 0. Base Knowledge](https://euidong.github.io/images/ml-thumbnail.jpg?imwidth=640)
Comments